Blue-green deployment keeps two identical production environments, blue and green, and routes traffic to one at a time. You push the new version to the idle environment, flip the load balancer, and you're live. If something breaks, you flip the switch back. That's the whole appeal: rollback is the same action as the promotion.
This works beautifully for stateless application servers. Databases are a different story. They're stateful, and both environments either share the same data or have to converge on it. The moment you run a schema migration against green, the blue app reading the same tables can break. This guide covers what makes database blue-green deployments hard in particular, and how to handle each piece without losing data.
What is blue-green deployment?
Blue-green deployment is a release strategy that keeps two production-equivalent environments. At any given moment, one of them, say blue, handles live traffic. The other, green, sits idle and is used to stage the next release.
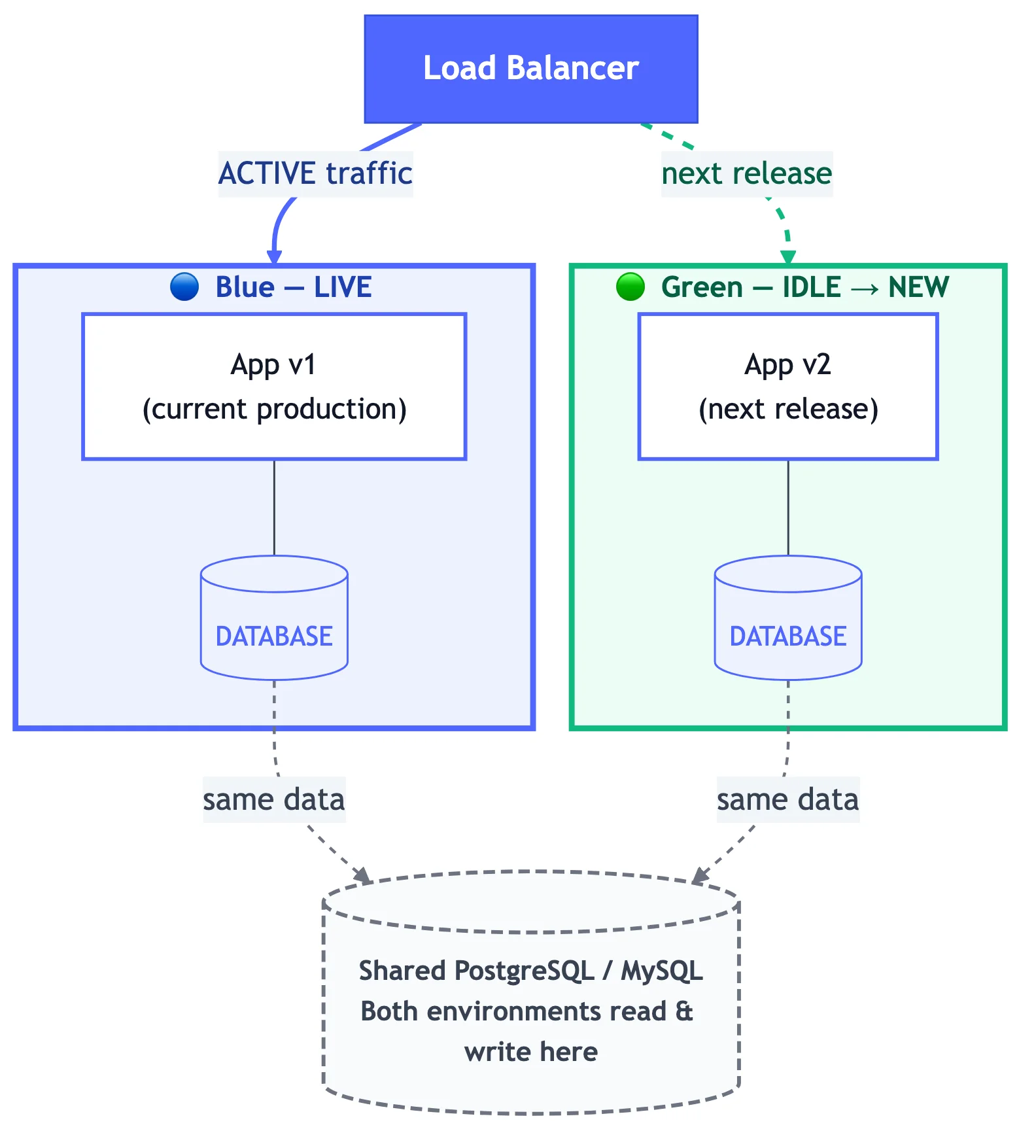 Blue-green deployment architecture: load balancer routing traffic to active blue environment while green receives the new release
Blue-green deployment architecture: load balancer routing traffic to active blue environment while green receives the new release
The release sequence:
- Deploy the new version to the idle environment (green).
- Run smoke tests against green while blue handles live traffic.
- Flip the load balancer from blue to green.
- Monitor green. If something breaks, flip back to blue.
- Once green is stable, blue becomes the new idle environment for the next release.
The big win is a near-instant, low-risk cutover. Because the rollback path is just flipping the load balancer back, which is the same operation as the promotion, the blast radius of a bad deploy stays bounded.
Why database blue-green deployments are uniquely hard
Application servers are stateless, so you can run version 1 and version 2 side by side, route traffic to whichever you want, and throw the other one away with no coordination. Databases don't give you that freedom. A few things break the clean picture.
Both environments point at the same data. Unless you provision two separate databases, which is expensive and brings its own sync headaches, blue and green read and write the same tables. Add a NOT NULL column to orders for green, and the blue application breaks the instant it tries to insert a row without that column.
Schema changes can't be rolled back by flipping a switch. If green's schema has a column blue doesn't know about, blue writes fail. If you drop a column green is still using, green breaks. The load balancer flip is reversible. The schema migration usually isn't.
There's a window where both versions run at once. During cutover, in-flight requests from blue are still finishing. You can't guarantee a clean break between old and new code, so any schema change that the old code can't tolerate will throw errors in that window.
Data written after cutover can't go back. Flip to green, let green write data in a new format, then flip back to blue, and blue may not understand what green wrote. Now you've corrupted your dataset.
None of these are fixable at the infrastructure layer. They come down to how you handle schema changes.
Making schemas backward-compatible: the expand/contract pattern
The expand/contract pattern, sometimes called parallel change, is the standard way to make schema migrations safe for blue-green and rolling deployments. The idea is to split a single schema change into phases, where each phase is compatible with both the old and the new application code.
Phase 1: Expand
Add the new structure without removing anything old. The database now supports both versions of the app at once.
Example: renaming a column user_name to username
-- Phase 1: Add the new column. Both old (user_name) and new (username) columns exist.
ALTER TABLE users ADD COLUMN username VARCHAR(255);
-- Backfill new column from old data
UPDATE users SET username = user_name WHERE username IS NULL;At this point the old app reads and writes user_name, the new app reads and writes username, and both work.
Phase 2: Deploy new application code
Deploy the new application version, the one that uses username, to the idle environment. Flip traffic to it. Now the expand-phase schema and the new app code are both live.
Monitor. If something breaks, flip back. The old column is still there and the old code still works.
Phase 3: Contract
After the new code has run cleanly for an acceptable monitoring period (hours or days, depending on how much risk you're willing to carry), remove the old structure.
-- Phase 3: Remove the old column now that no running code references it
ALTER TABLE users DROP COLUMN user_name;This cleanup is safe because no deployed code references user_name anymore.
Rules for expand/contract
The pattern only holds if every schema change follows these rules:
| Change | Safe to deploy directly? | Expand/contract needed? |
|---|---|---|
| Add nullable column | Yes | No |
| Add NOT NULL column with default | Yes (with care) | Recommended for large tables |
| Rename column | No | Yes |
| Drop column | No | Yes (contract phase only) |
| Add index (CONCURRENTLY) | Yes | No |
| Change column type | No | Yes |
| Add foreign key constraint | Caution | Yes, if old code may violate it |
The test to keep in mind: can both the current version and the new version of the application code run correctly against this schema at the same time?
Step-by-step: database blue-green deployment with Bytebase
Bytebase maps onto the blue-green pattern through its multi-environment deployment pipeline. Each environment (dev, staging, production-blue, production-green) is its own target in Bytebase, with its own approval and deployment rules.
Set up environments
In Bytebase, create four environments in order: Dev, Staging, Production-Blue, Production-Green. Each one maps to a database instance.
Submit a migration
A developer submits the schema change through Bytebase. The change moves through the pipeline: Dev first, then Staging, then the production environments in sequence.
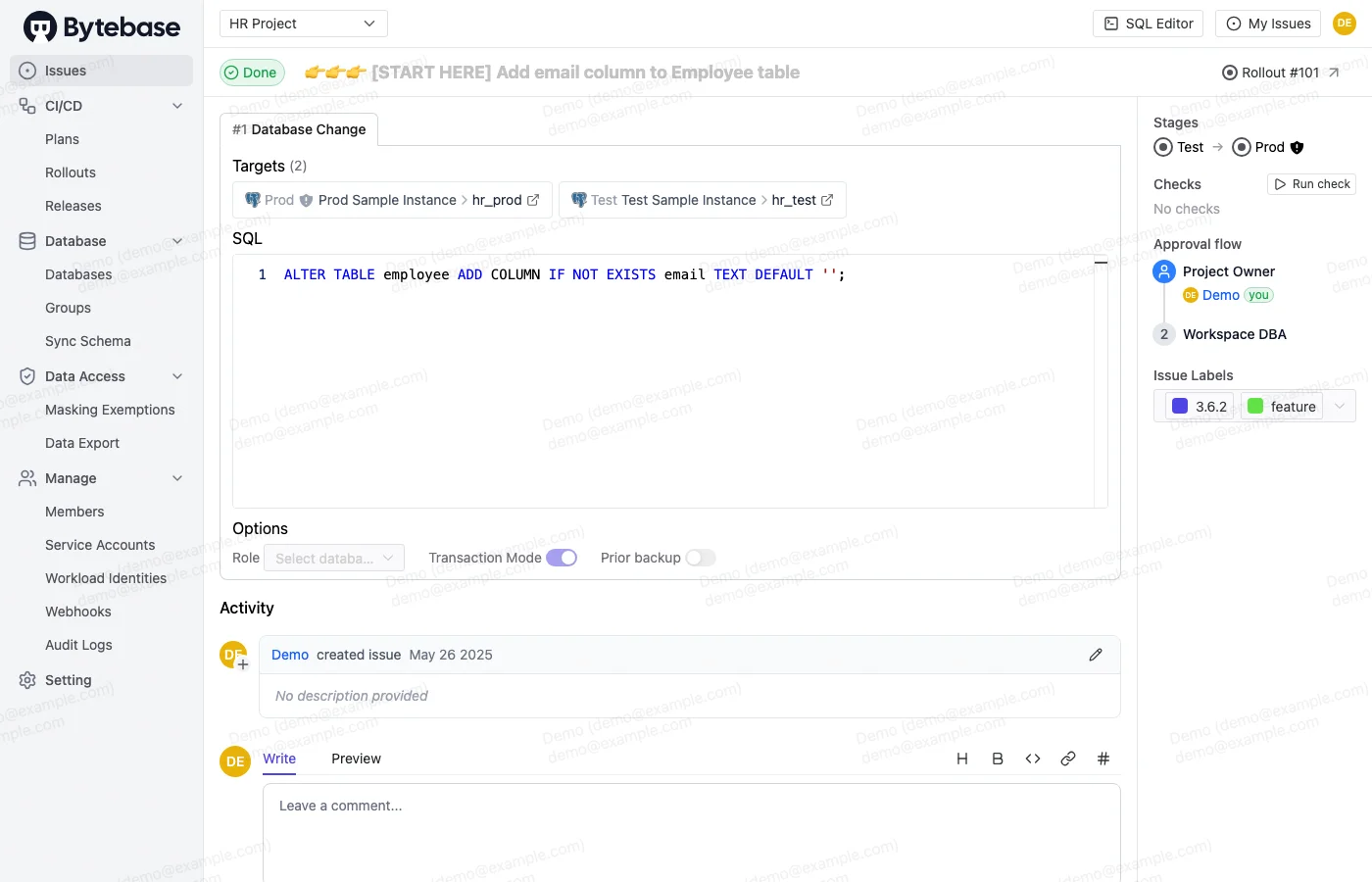 Bytebase issue detail showing a schema migration with SQL diff, environment deployment stages, and DBA approval controls
Bytebase issue detail showing a schema migration with SQL diff, environment deployment stages, and DBA approval controls
Before the change reaches any environment, Bytebase's SQL review rules run automatically. They check for:
- Missing
WHEREclauses onUPDATEorDELETE NOT NULLcolumns added without defaults- Statements that lock tables
- Naming convention violations
Any violation blocks the issue from advancing until it's resolved.
Deploy to the idle environment
When the change reaches the production stage, deploy it to the idle environment first (say, Production-Green). Production-Blue is still live and serving traffic.
Bytebase records the exact SQL applied, the timestamp, and who approved it. The change shows up in the change history before it goes anywhere near live traffic.
Flip and monitor
After you've deployed to Production-Green and validated it, flip the load balancer. Production-Green is now live and Production-Blue is idle.
If the new release has a problem, flip back. The schema is still in expand phase, so both old and new code work against it.
Run the contract phase
Once the new code has been stable for your monitoring period, submit the contract migration through Bytebase. This drops the old columns or constraints the old application code relied on. Route it through the same pipeline and the same review process.
The full database change management workflow in Bytebase means every migration, the contract phase included, leaves an approval trail. If something goes wrong weeks later, you have an exact record of what changed, when, and who signed off on it.
Blue-green vs. canary vs. rolling for database changes
These three strategies place different demands on schema compatibility.
| Strategy | Traffic pattern | Schema compatibility requirement |
|---|---|---|
| Blue-green | All-or-nothing cutover | Schema must support both versions simultaneously during cutover window (minutes to hours) |
| Canary | Small percentage routed to new version, gradually increased | Schema must support both versions for the entire canary period (hours to days) |
| Rolling | Instances updated one at a time, old and new code running together | Schema must support both versions for the entire rollout period (minutes to hours per instance) |
Blue-green has the shortest overlap window, which makes it the easiest of the three to reason about. Canary has the longest, because old and new code run together for days, so every schema change in a canary deployment has to stay backward-compatible for the whole observation window.
All three benefit from expand/contract. Blue-green makes the contract phase simplest, because there's a clear moment in time when no blue code is left running.
Common pitfalls and how to avoid them
Skipping the expand phase and deploying schema changes directly
The most common mistake is treating database migrations like application deployments: ship the new schema to green, flip traffic, call it done. If the schema removes something the old code still needs, blue requests fail during the cutover window. Always expand first.
Long-running migrations holding locks
ALTER TABLE on a large table can hold an exclusive lock for minutes, blocking every read and write. In PostgreSQL, use ADD COLUMN with the default set separately rather than inline on the ALTER, and build indexes with CREATE INDEX CONCURRENTLY. Test how long the migration takes in staging against a production-sized dataset before you promote it.
Forgetting the contract phase
Expand adds columns and keeps the old ones around. Skip the contract phase and the database slowly fills up with dead columns, old tables, and orphaned indexes. Treat the contract migration as a required follow-up, not optional cleanup. Track it explicitly, in a Bytebase issue or a ticket, so it doesn't quietly fall off the list.
Not testing rollback
The whole value of blue-green is the rollback path. If you've never actually flipped back, you don't really know it works. Put a rollback test in your deployment runbook: flip to green, run smoke tests, flip back to blue, run smoke tests again. Validate the path before you need it in the middle of an incident.
Schema drift between environments
If dev, staging, and production-blue have drifted apart, a migration that passes dev can still fail in production. Database schema drift is a silent killer in deployment pipelines. Bytebase's drift detection checks each environment against the expected schema state and flags discrepancies before a migration runs.
Over-engineering the deployment infrastructure
Blue-green at the database layer doesn't require two physical database clusters. Most teams run it as two logical environment slots in their deployment pipeline, pointing at the same underlying database instance with schema changes managed carefully. Physical cluster duplication only makes sense if you genuinely need data isolation between environments, which is rare.
Blue-green deployment shrinks application-tier release risk down to a load balancer flip. The database tier asks for more: expand/contract migrations, backward-compatible schema changes, and a contract phase you actually follow through on. The tooling handles the mechanics, Bytebase for migration management and your load balancer for traffic routing. The real work is in the schema design.
For a closer look at the multi-environment deployment workflow in Bytebase, see database multi-environment deployments. For the CI/CD integration that feeds schema changes into this pipeline, see how to build a CI/CD pipeline for database schema migration.