Database schema drift or just schema drift is the case where the actual schema in the live database (the actual state) is different from the source of truth (the desired state). It's also one of the most frequent root causes of the database related outages.
The live database part is easy to understand:
- For MySQL, it's the output of
mysqldump --no-data - For PostgreSQL, it's the output of
pg_dump --schema-only
While the source of truth part is more complex...
The source of truth
One may first wonder why we need to keep a separate source of truth. The reason is because the schema in the live database may not always be the desired state. Human error or software bugs could both accidentally change the database schema. So it's better to have a separate source of truth, this idea is similar to the classic double-entry bookkeeping used in accounting.
Naturally, a good place to store this source of truth is the version control system (VCS), the same place where the application code is stored. This is known as database-as-code, a GitOps practice. Solutions like Liquibase, Flyway support this approach. Bytebase also supports this and even go a step further to provide point-and-click UI to configure this.
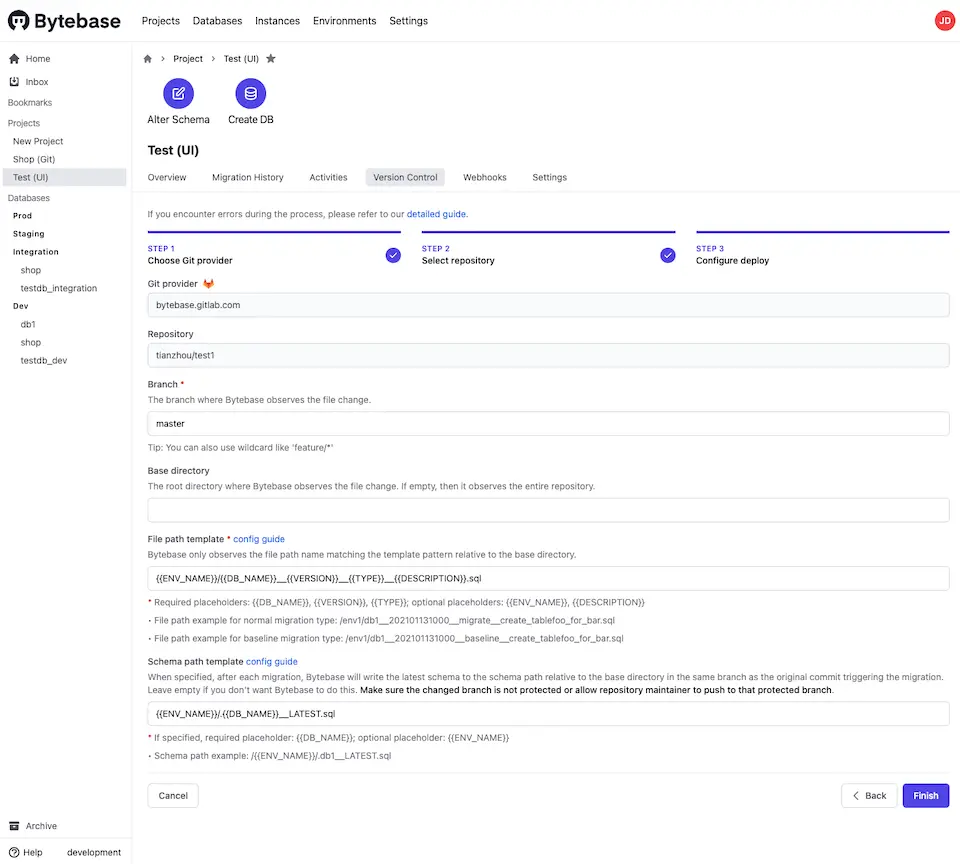
The format of source of truth
After we figure out where to store the source of truth, next we need fo decide which format to use as the source of truth. There are 2 approaches here, state-based and migration-based, long story short:
- State-based approach stores the desired end state of the entire schema in the code repository
- Migration-based approach stores the migration scripts in the repository. Each script contains a set of DDL statements such as CREATE/ALTER/DROP TABLE. The desired schema state is achieved by executing each of those scripts in a deterministic order.
State-based approach is a more intuitive format since a single file corresponds to a database schema. However, state-based approach has its limitation. e.g. it can't distinguish between table rename and drop/create table. Bytebase supports both approaches.
Schema drift detection
Using migration-based approach makes drift detection harder. System needs to derive the desired database schema from all migration files, and then compare it with the actual schema in the live database to detect the drift.
Bytebase optimizes this process by introducing the schema snapshot and write back feature:
- For every schema migration, Bytebase will record the schema snapshot.
- If team manage database schema under version control system, they can configure Bytebase to write the schema snapshot back to the repository at a specified path. Below shows an example how Bytebase writes back the full schema snapshot at the user configured path.
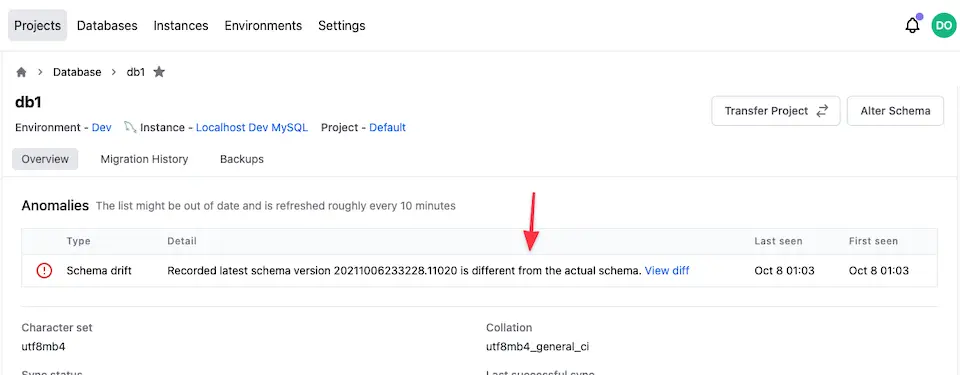
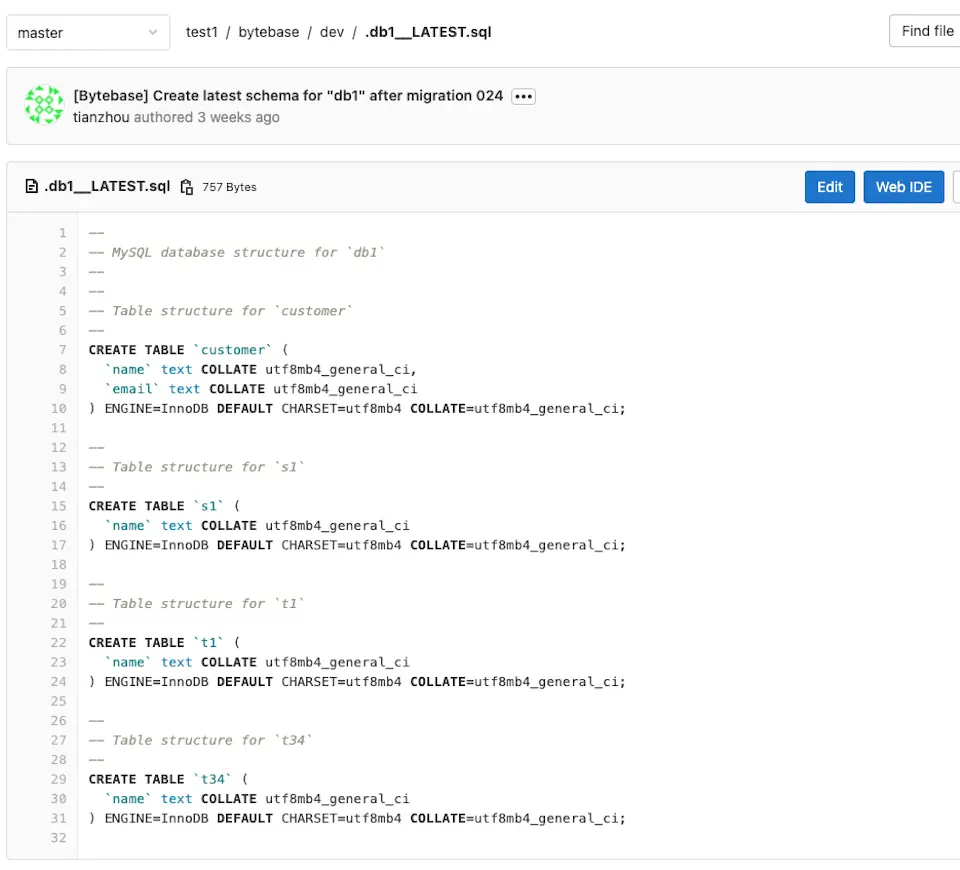 And by leveraging the schema snapshot, Bytebase continuously compare between the schema snapshot and the actual database schema in the live database and report drift once found👇
And by leveraging the schema snapshot, Bytebase continuously compare between the schema snapshot and the actual database schema in the live database and report drift once found👇
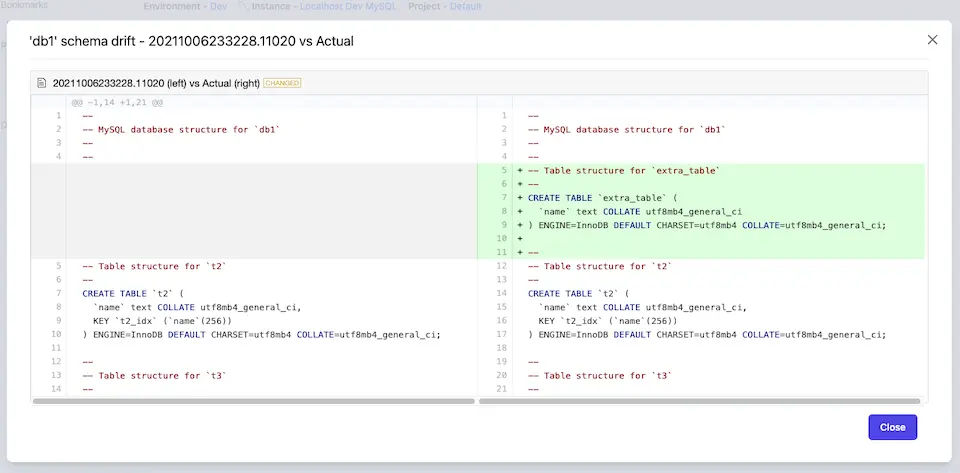
 The detailed drift👇
The detailed drift👇
Summary
Database schema drift is one of the most frequent root causes of the database related outages. Recording the desired database schema state in the version control system like GitLab is the first stepping stone to tackle it. Bytebase takes the extra mile to present an easy-to-use UI for users to adopt this practice and surfaces detailed schema drift info once detected.
If this interests you, please do try Bytebase Cloud or use 1 liner to deploy yourself.
Further Readings
- What is Database Change Management?
- Database-as-Code
- Bytebase Database-as-Code VCS integration
- Database Version Control, State-based or Migration-based?