Sensitive columns — SSNs, credit cards, emails, addresses — must stay queryable for support, analytics, and development. Broad cleartext access is not the answer. Data masking is. For some workloads (GDPR, HIPAA, PCI), masking is also a legal requirement.
Postgres ships no masking primitives in core. Two options stand out: PostgreSQL Anonymizer, a community extension that lives inside the database, and Bytebase Dynamic Data Masking, a policy layer in front of it. This post compares them.
PostgreSQL Anonymizer
PostgreSQL Anonymizer is a community extension by Damaen and the team at Dalibo. Version 2.0 is a full rewrite in Rust on top of the PGRX framework — improved memory safety, lower overhead, and a cleaner extension surface than the SQL/PL-pgSQL predecessor.

Masking configuration is stored in PostgreSQL Security Labels. The pg_seclabel mechanism was designed for security modules, but it generalizes into a transactional, MVCC-aware way to attach custom metadata to any database object — no core patches required. Anonymizer pioneered this pattern for masking; pgEdge applies the same primitive to replication metadata.
Five strategies
Anonymizer 2.0 ships five distinct masking strategies. Pick by access pattern.
- Dynamic Masking. A role is declared
MASKED. Sessions running under that role see masked output; other roles see cleartext. Role-based, transparent, no application changes. - Static Masking. Rewrite the data in place. Destructive — only for clones and lower environments. Slow on large tables; Postgres rewrites every row containing at least one masked column.
- Anonymous Dumps.
pg_dump_anonemits an anonymized dump for downstream consumers. The original cluster stays clean. - Masking Views. Views over base tables that apply masking expressions. Grant access to the views, not the tables.
- Masking Data Wrappers. Foreign data wrappers that mask on read across federated sources.
Masking transformations
Anonymizer 2.0 bundles eight transformation families: substitution, randomization, faking, pseudonymization, partial scrambling, shuffling, noise addition, generalization. The 2.0 faker is more realistic than 1.x — locale-aware data generators replace the older static dictionaries.
-- 1. Load the extension and declare a masked role.
CREATE EXTENSION anon CASCADE;
SELECT anon.start_dynamic_masking();
CREATE ROLE analyst LOGIN PASSWORD '…';
SECURITY LABEL FOR anon ON ROLE analyst IS 'MASKED';
-- 2. Attach a masking rule via a security label on the column.
SECURITY LABEL FOR anon ON COLUMN customers.email
IS 'MASKED WITH FUNCTION anon.fake_email()';
-- 3. analyst sees fake emails; postgres sees real ones.
SET ROLE analyst;
SELECT email FROM customers LIMIT 1;
-- email
-- ------------------------------
-- irma.fritsch@hahn-davis.testWhat's new in 2.0
- Role-based transparent dynamic masking — formerly tied to a single masked role; 2.0 supports nuanced role policy.
- Multiple masking policies — define and switch between policy sets per workload (e.g. one for analysts, another for support).
- Anonymous dump as a first-class workflow — not a bolt-on script.
- Debian packages — distribution-installable; no manual compile.
Limitations to know
- GUI client compatibility. Per the docs, certain query patterns issued by tools like DBeaver or pgAdmin can behave unexpectedly under dynamic masking.
- View inventory. Masking Views still grow with every variation. Schema changes ripple through the view set.
- Per-extension, per-cluster. Anonymizer runs inside one Postgres cluster. Across a fleet of Postgres + RDS + Aurora + managed Postgres flavors, the extension and the labels must be maintained on each one.
- Postgres only. A heterogeneous fleet (Postgres + MySQL + Snowflake) needs a separate masking solution for the non-Postgres engines.
Bytebase Dynamic Data Masking

Anonymizer is an extension. Extensions require install rights, superuser, and the ability to load a shared library — none of which managed Postgres guarantees. RDS, Cloud SQL, and AlloyDB control the allowlist. Some flavors omit anon entirely. Minor-version upgrades can disturb extension state. Anonymizer's own docs flag that dynamic masking behaves unexpectedly under DBeaver and pgAdmin.
Bytebase Dynamic Data Masking needs no extension. No SECURITY LABEL DDL. No superuser. Policies live in Bytebase. Queries route through Bytebase's SQL Editor. Masking runs in the result path — outside Postgres. The same policy applies across community Postgres, RDS, Aurora, Cloud SQL, AlloyDB, and managed forks where Anonymizer cannot install. Policy changes and exemption requests run through a built-in workflow — Request. Review. Approve. — every step audited.
Policies compose from three layers, evaluated in fixed precedence: Masking Exemption > Global Masking Rule > Column Masking.
- Global Masking Rule. Workspace-level. Rules evaluate top-down. First match wins. Match conditions span environment, project, database, and data classification. Each match applies a Semantic Type, which selects a masking algorithm — full, partial, MD5, range, or custom.
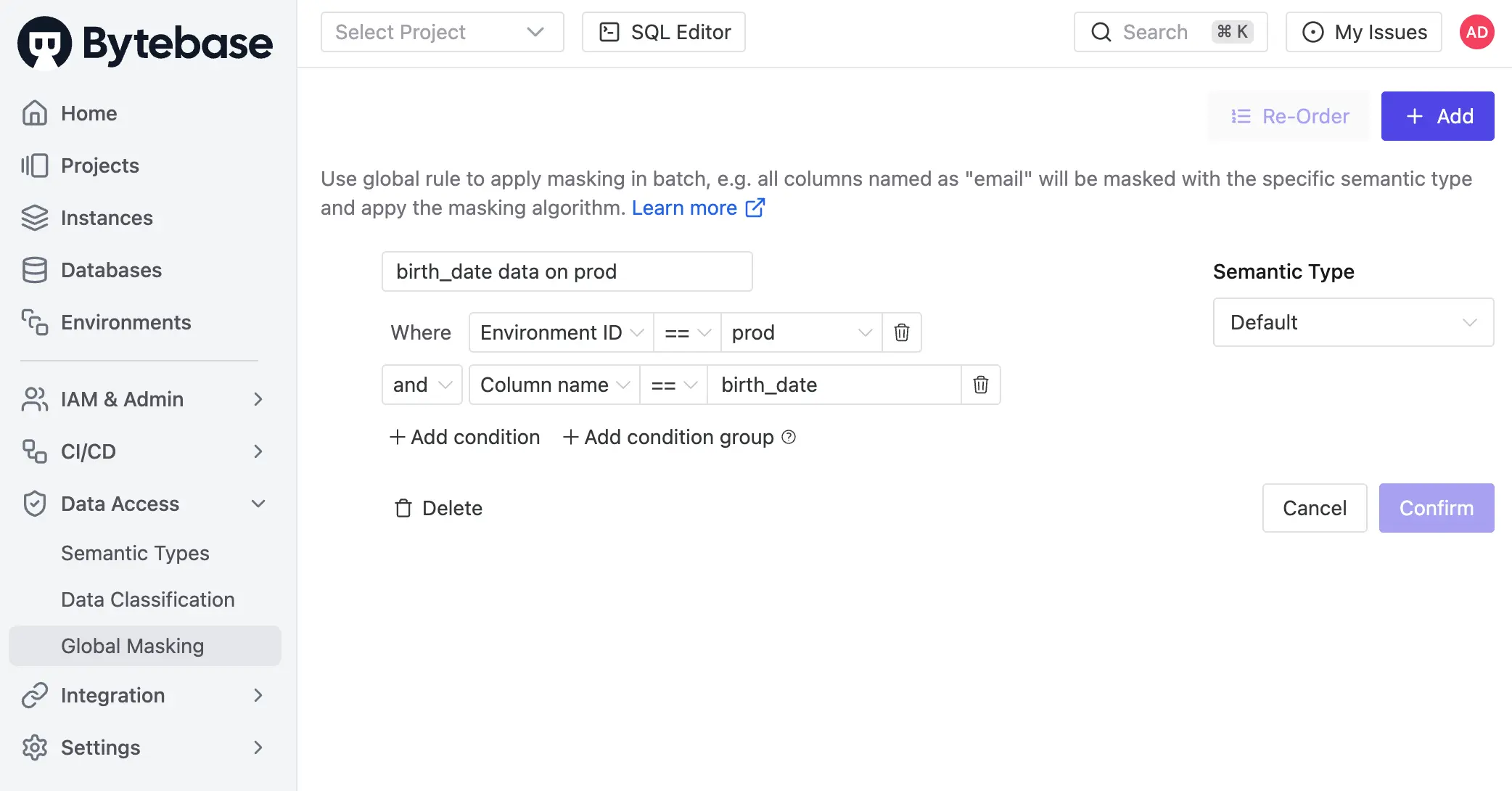
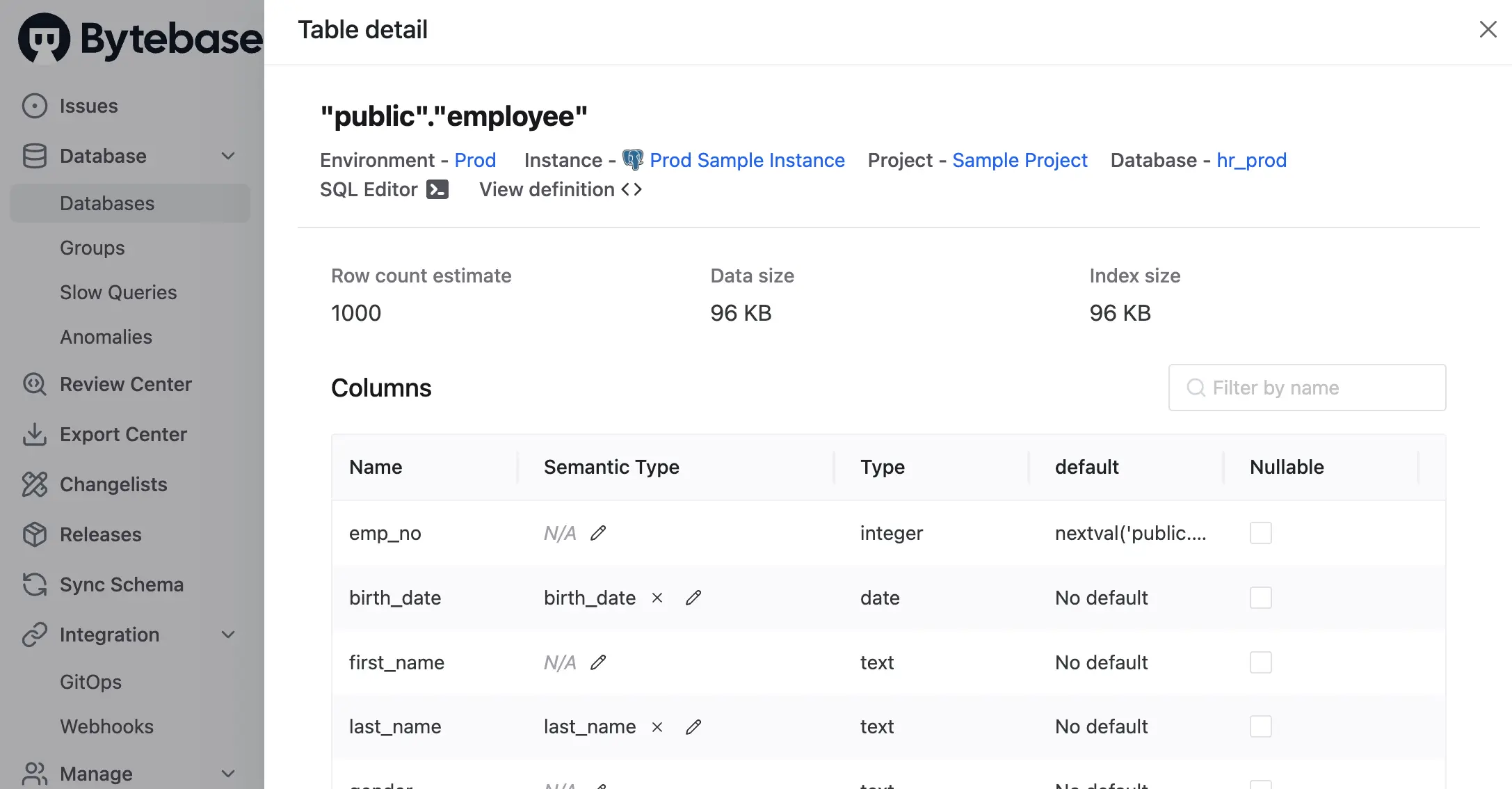
- Column Masking. Project-level override on a specific column when the global rule does not apply.
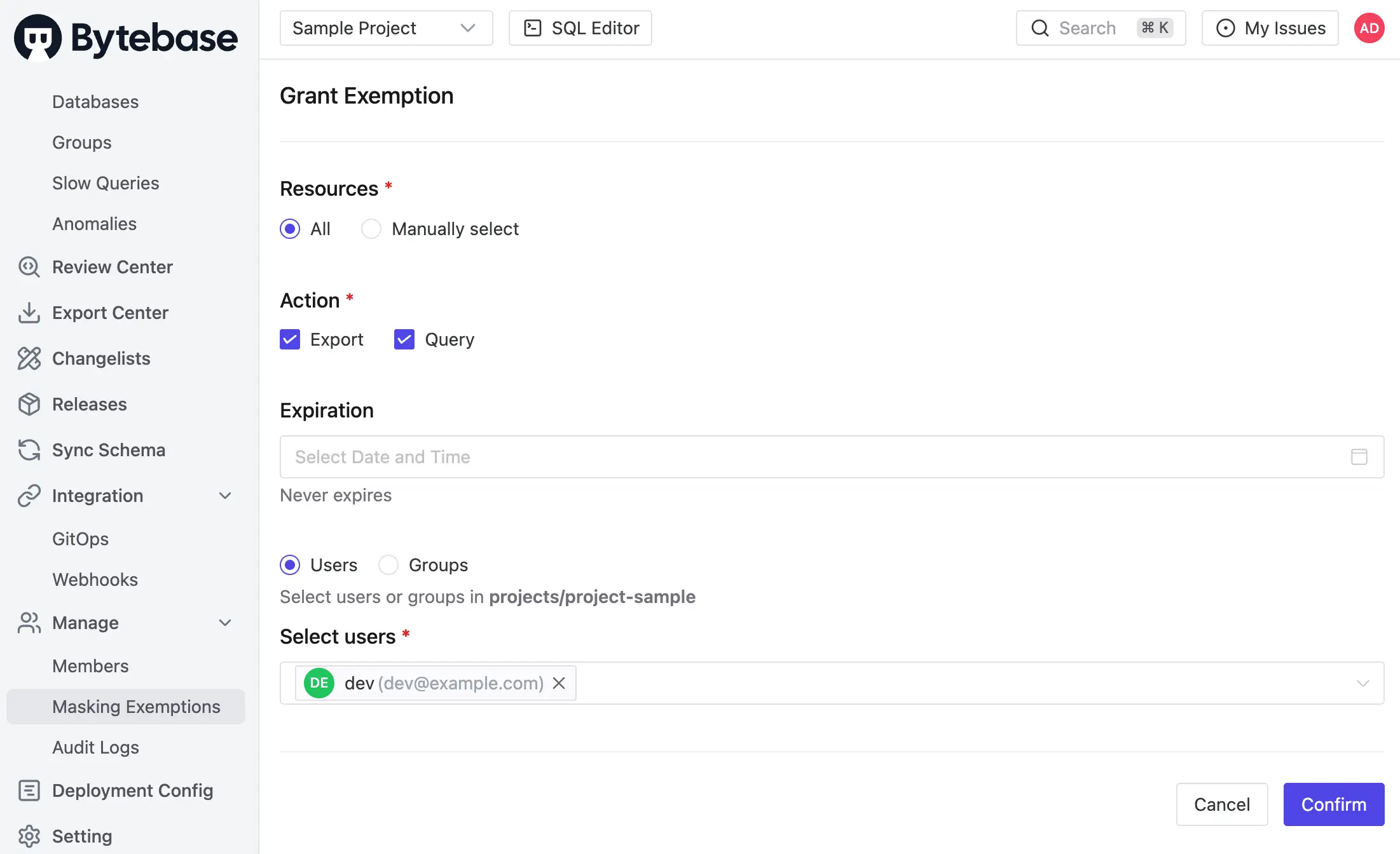
- Masking Exemption. Named users receive time-bound
QueryorExportexemptions to specific databases or tables. Service accounts are not eligible. Every grant logged. Every access logged.
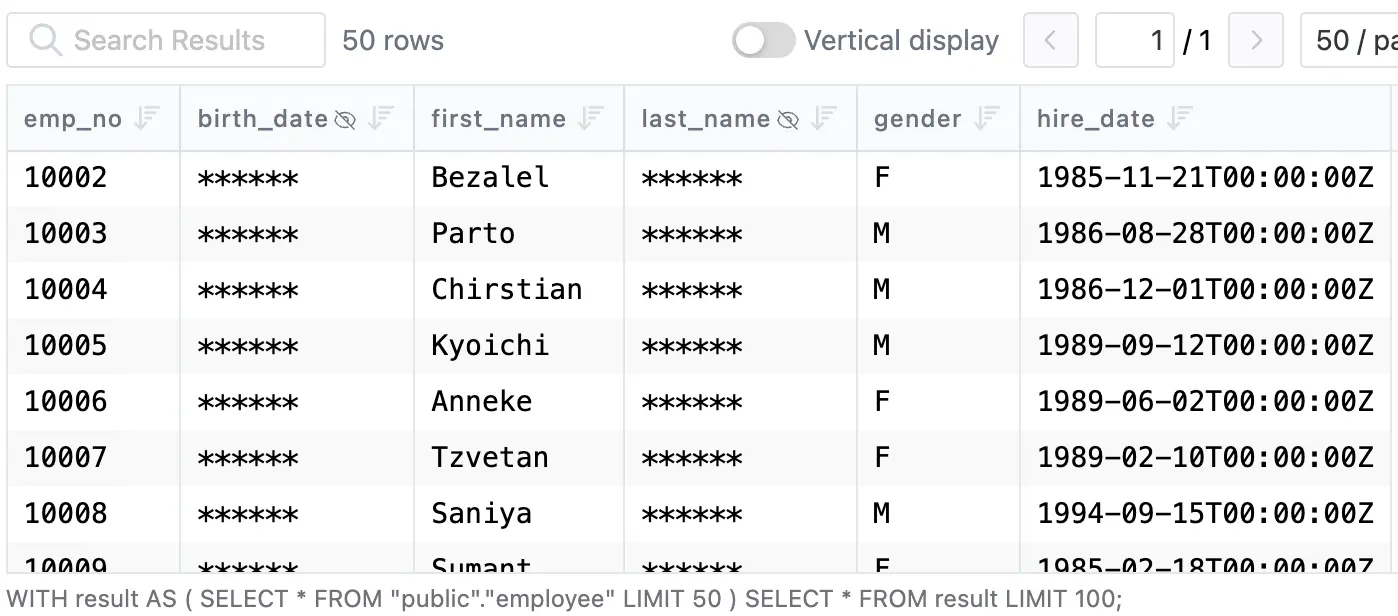
Masking propagates. When a column is masked, the policy extends to every view and derived structure that depends on it. No view inventory. No security-label drift across upgrades.
Policies can also be codified via GitOps.
Masking decisions are recorded in the audit log. Every SQL execution entry carries per-column masking metadata — masked columns, Semantic Type, matching rule — alongside user, source IP, statement, and row count. Granted exemptions, used exemptions, and policy edits are first-class audit events.
Enforcement boundary: Bytebase masks queries routed through the SQL Editor. Direct connections to Postgres bypass it. For destructive workflows — anonymized dumps, lower-environment refresh — Anonymizer remains the right tool where it installs. For human query traffic with approval and audit, Bytebase covers the path the extension cannot reach on managed Postgres.
Comparison
| PostgreSQL Anonymizer 2.0 | Bytebase Dynamic Data Masking | |
|---|---|---|
| Compatibility | Postgres clusters with anon extension | All PostgreSQL distributions ⭐️ |
| Mechanism | Security labels + extension functions ⭐️ | Policy in Bytebase, applied at SQL Editor |
| Enforced at | Database, every read path ⭐️ | SQL Editor |
| Strategies | Dynamic, static, dumps, views, FDW ⭐️ | Dynamic only |
| Policy mgmt | SQL SECURITY LABEL per object | Centralized UI, grants, audit log ⭐️ |
| Workflow | DDL only | Request. Review. Approve. ⭐️ |
| Row-level filter | No (pair with RLS) | No (pair with access policy) |
| Price | Free ⭐️ | Paid |
Picking one
- Single Postgres cluster, masking must enforce regardless of client. Use PostgreSQL Anonymizer 2.0. Dynamic masking for analyst access.
pg_dump_anonfor environment clones. Static masking only when the data must be destroyed. - Mixed fleet — Postgres alongside MySQL, Snowflake, RDS, Aurora, or managed forks. Use Bytebase. One policy model. Every engine. Audited grants for every unmask, recorded in the same place as your access logs.
- Both. Anonymizer handles destructive workflows (anonymized dumps, lower-environment refresh); Bytebase handles human query traffic with approval and audit. They compose.
Try Bytebase Dynamic Data Masking with this tutorial, or see how it works fleet-wide on PostgreSQL data masking.