
Database access control is a constant headache for DBAs and platform engineering teams. On the one hand, the ones overseeing the databases prefer centralized control; but on the other hand, the ones using the database would like database access anytime, anywhere.
The extreme of the former is that all access to the database needs to be approved by the database team, which leads to that team becoming the bottleneck, slowing down product delivery, and constantly being complained about by the devs.
The latter, if taken to the extreme, is that database access is scattered everywhere, which causes potential data leaks. Without a standardized change process, this could also lead to serious incidents such as accidentally dropping databases.

So, is there an ideal solution that can balance both control and efficiency?
Let's first dissect the scenarios requiring database access, afterwards, we will propose our solutions.
Access Control Scenarios for Databases
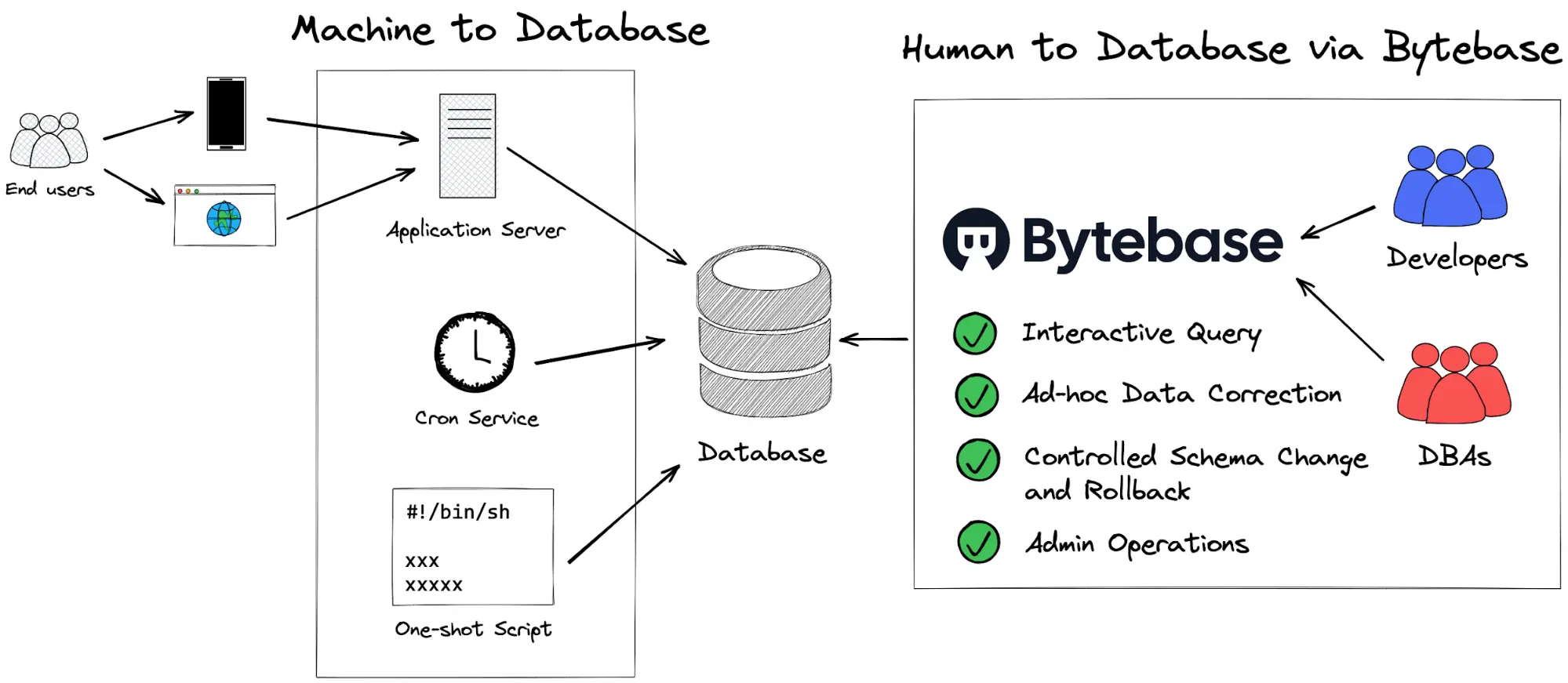
There are two categories for accessing databases: Machine to Database and Human to Database.

Machine to Database
End user-initiated
End user initiates the action from the web or mobile clients, which translates to the create/read/update/delete (CRUD) operations from the Application Server to the database. For example, a record will be generated in the database when someone places an order through a takeaway app.
Change on deploy
Sometimes when the software version is upgraded, database schema or data also changes. The common practice is making changes before running the new version for the first time. Many application development frameworks and ORMs have built-in capabilities, such as Ruby on Rails’ Active Record Migrations, and django’s Migrations.
Cron jobs
For example, a financial system periodically performs automated reconciliation operations and generates records in the database or a downstream data pipeline that synchronizes data from the online database.
One-shot/on-demand executions
Such as data cleanup/migration/revision involving complex business logic. These operations are packaged into separate scripts or command line applications (CLI) that are run only when needed.
Human to Database
Offline schema change
Users sometimes also connect to the database directly and perform schema changes. Wrongly executed DROP TABLE / DATABASE schema change operation can result in serious or even irreparable damage.
Ad-hoc data correction
Connect directly to the database and perform DML/DDL.
Interactive query
Connect directly to the database and query the data.
Admin operations
The DBA connects to the database to perform admin operations, such as terminating SQL statements that take too long to execute.
For any of the above interactions, connecting directly to the database manually to perform operations is a high-risk behavior, so usually, the company sets up a bastion or jump server. This way, organizations can have some oversight and control of the database operations. However, setting up a jump server also brings inconveniences to users and introduces additional management burdens. For example, you need to consider whether to set up a separate jump server for database access or to reuse the shared jump server for accessing other production systems.
Solutions
Let’s clarify a few things first:
-
Accessing a database, especially in production, is a high-risk operation. Even if there’s no change involved, a single SELECT statement can bring down the whole database and cause serious failures. Therefore, whenever possible, control is necessary.
-
Minimize (or, better, avoid) manually connecting to the database. Humans make mistakes, and manually connecting to the database also means that the database access information has to be distributed to individuals, which is a receipt for data leakage.
-
It is unavoidable for the applications to access the databases (otherwise, they won’t run). However, database schema changes can be decoupled from the new application version deployment. Moreover, decoupling these two actions allows you to better control the change process and deal with possible rollbacks.
Bytebase can cover all manual database access scenarios and unify schema changes into a controlled process.
Below table shows how each Human to Database scenario is covered by the corresponding Bytebase feature:
| Scenario | Targeting Role | Bytebase Feature |
|---|---|---|
| Offline Schema Change | Developer and DBA | Schema Change Workflow |
| Ad-hoc Data Correction | Developer and DBA | Data Change Workflow |
| Interactive Query | Developer and DBA | SQL Editor Read-Only mode |
| Admin Operations | DBA | SQL Editor Admin mode |
Bytebase offers:
- A two-tier permission model. One at the workspace level for global permissions and another at the project level for specific projects. These two levels of permissions correspond to the central DBA/platform engineering team and the development team of each application project group, respectively.

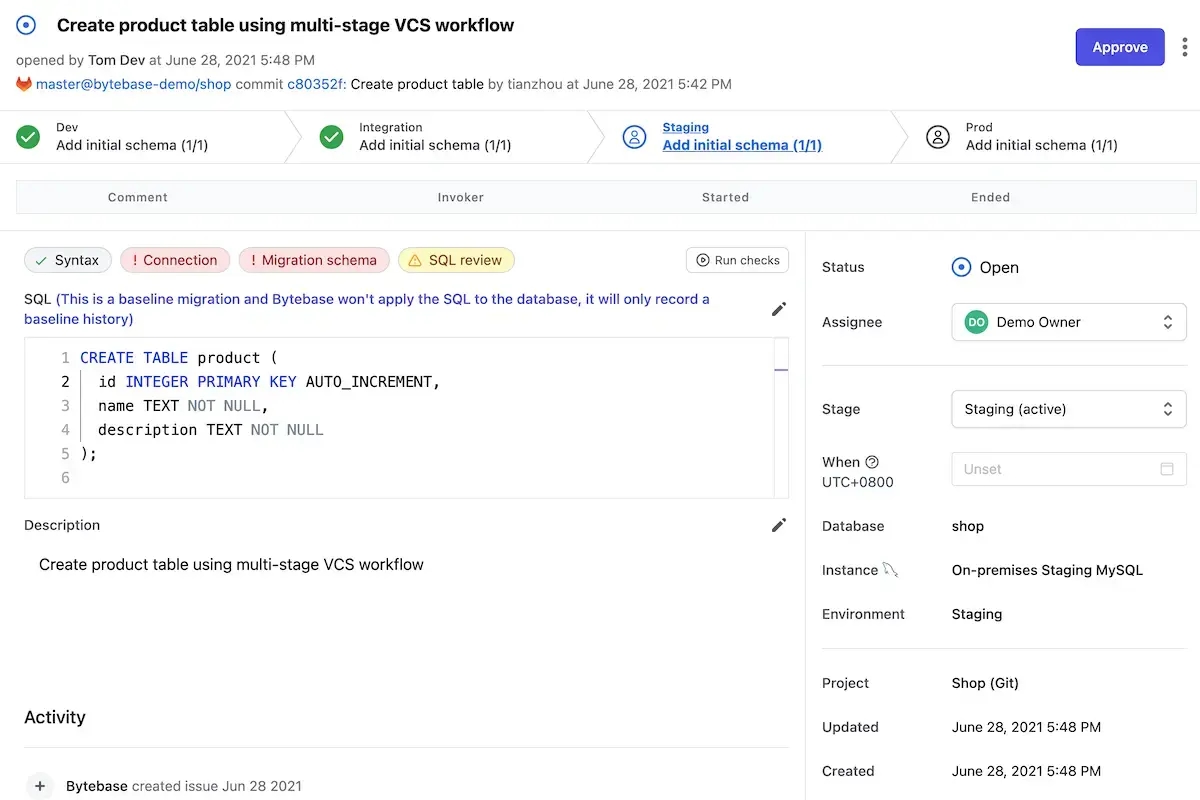
- A UI to manage database schema and the change review process. It also integrates with GitLab & GitHub, providing a Database-as-Code process #GitOps.
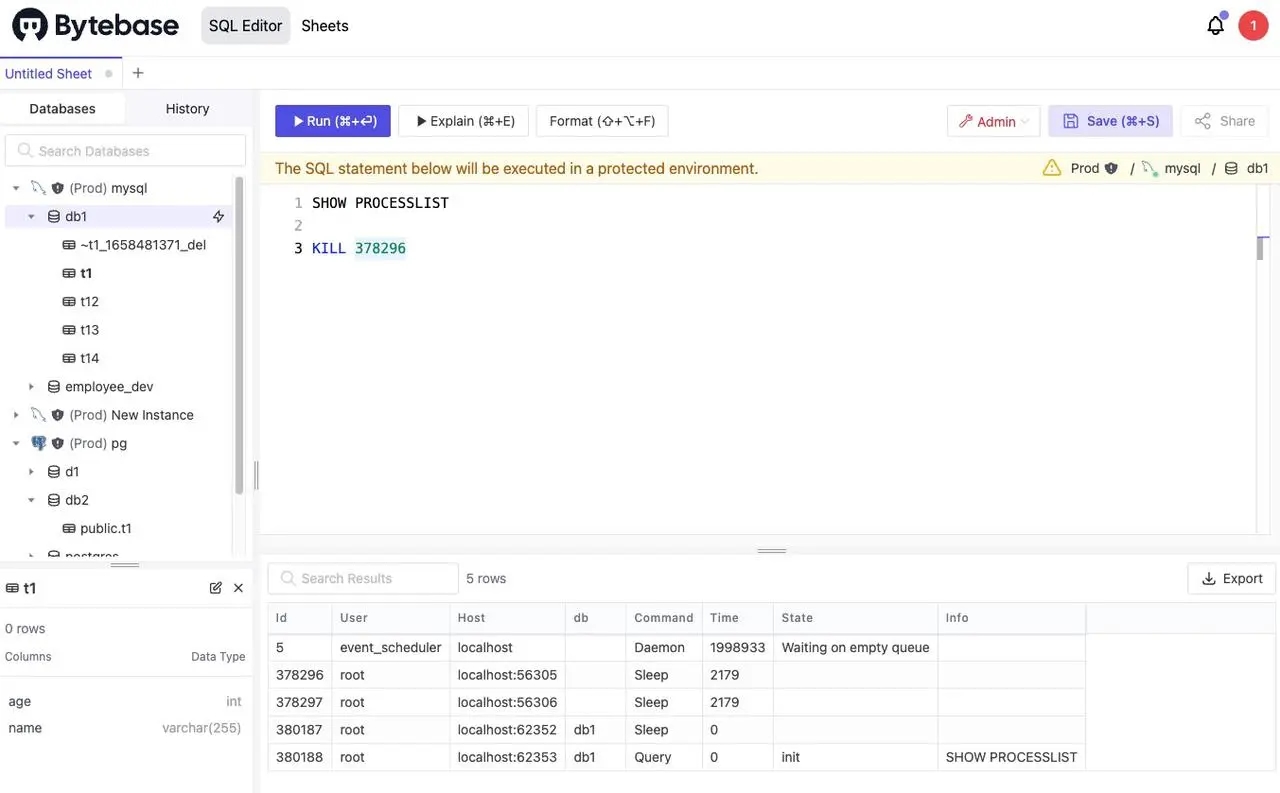
- A SQL Editor that allows developers to perform SELECT queries. For DBAs, you can enable the
Adminmode to execute database administrative commands.
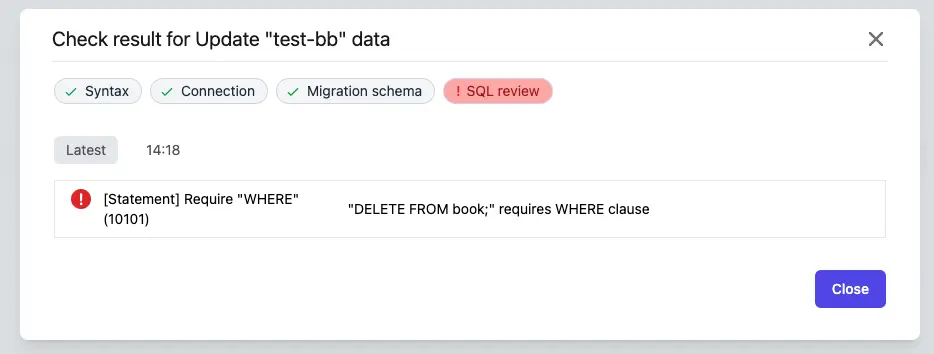
- SQL Review rules. For example, the following rule prevents users from executing DELETE statements without WHERE. You can also configure different rules for different environments, such as
dev,test,prod, etc.
- SQL review policies. For example, for the
devenvironment, you can skip review from the DBA; for theprodenvironment, review from either the DBA or project owner is mandatory.

Summary
You can never be too careful when it comes to operating databases, but while maintaining necessary caution, teams want efficiency. Bytebase is the only Database CI/CD solution in the CNCF Landscape, providing an all-in-one database lifecycle management capability to accelerate software delivery.

For DBAs and platform engineering teams, Bytebase enables you to have control over all human database access paths. For the application developers who need to use the database, Bytebase provides a developer-friendly UI to help you develop efficiently and safely.
Move fast and don't break things!


