What is Schema Synchronization?
Schema synchronization can calculate the difference between two database schemas, and generate the SQL statements representing the diffs. Thus, people do not need to write the migration SQL statements by hand.
Overview
Bytebase has supported MySQL schema synchronization since v1.8.0. Below is the workflow.
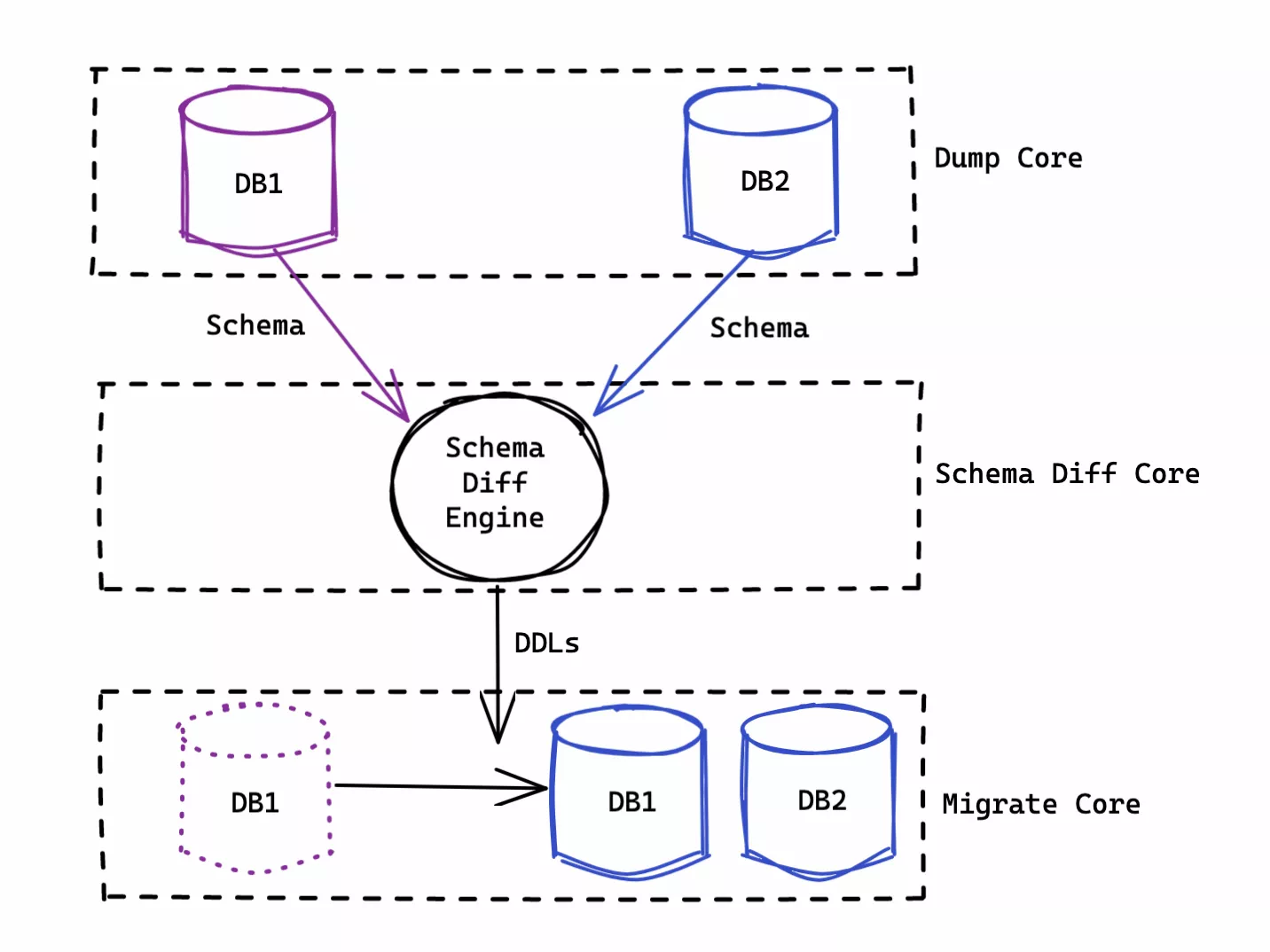
Schema Diff Engine
SQL AST
Bytebase first dumps the database schema and converts them into abstract syntax tree (AST) via the parser.
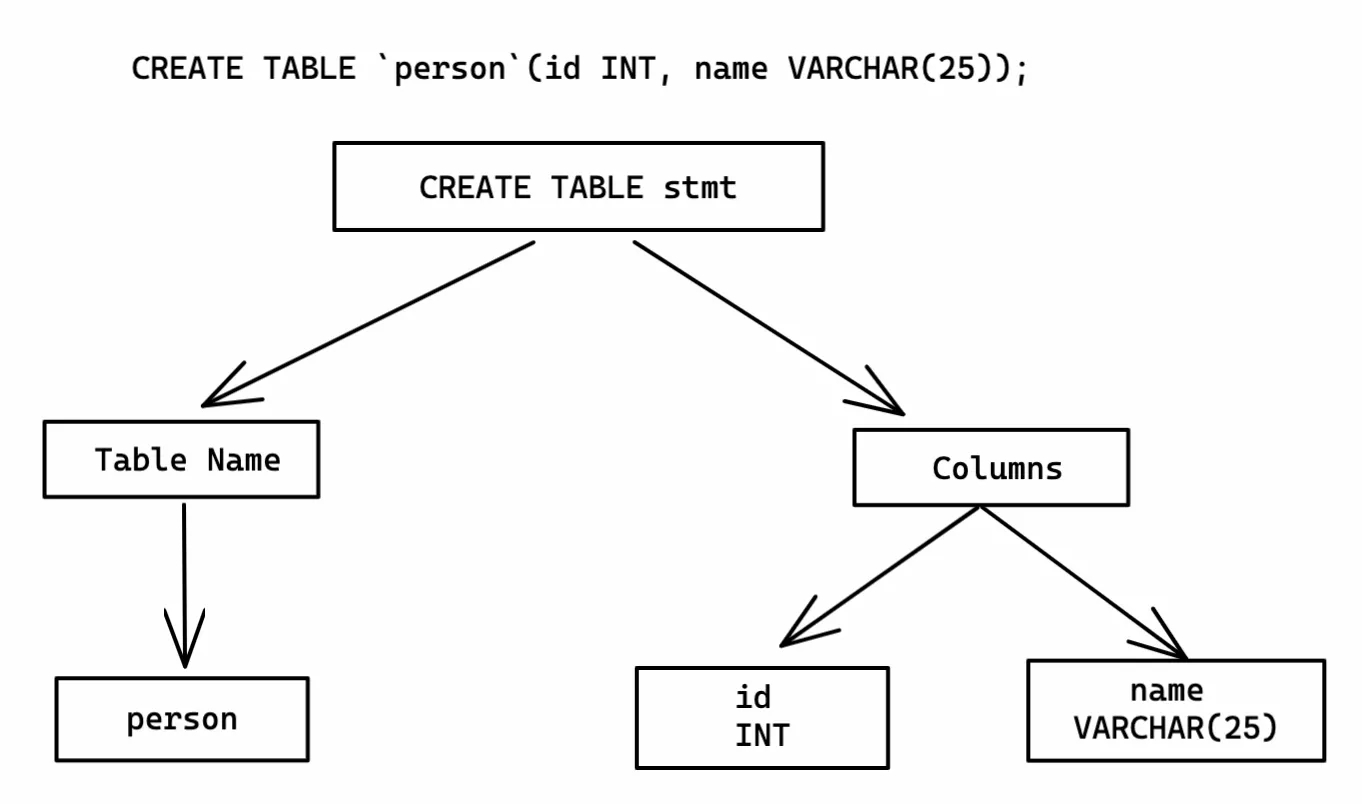
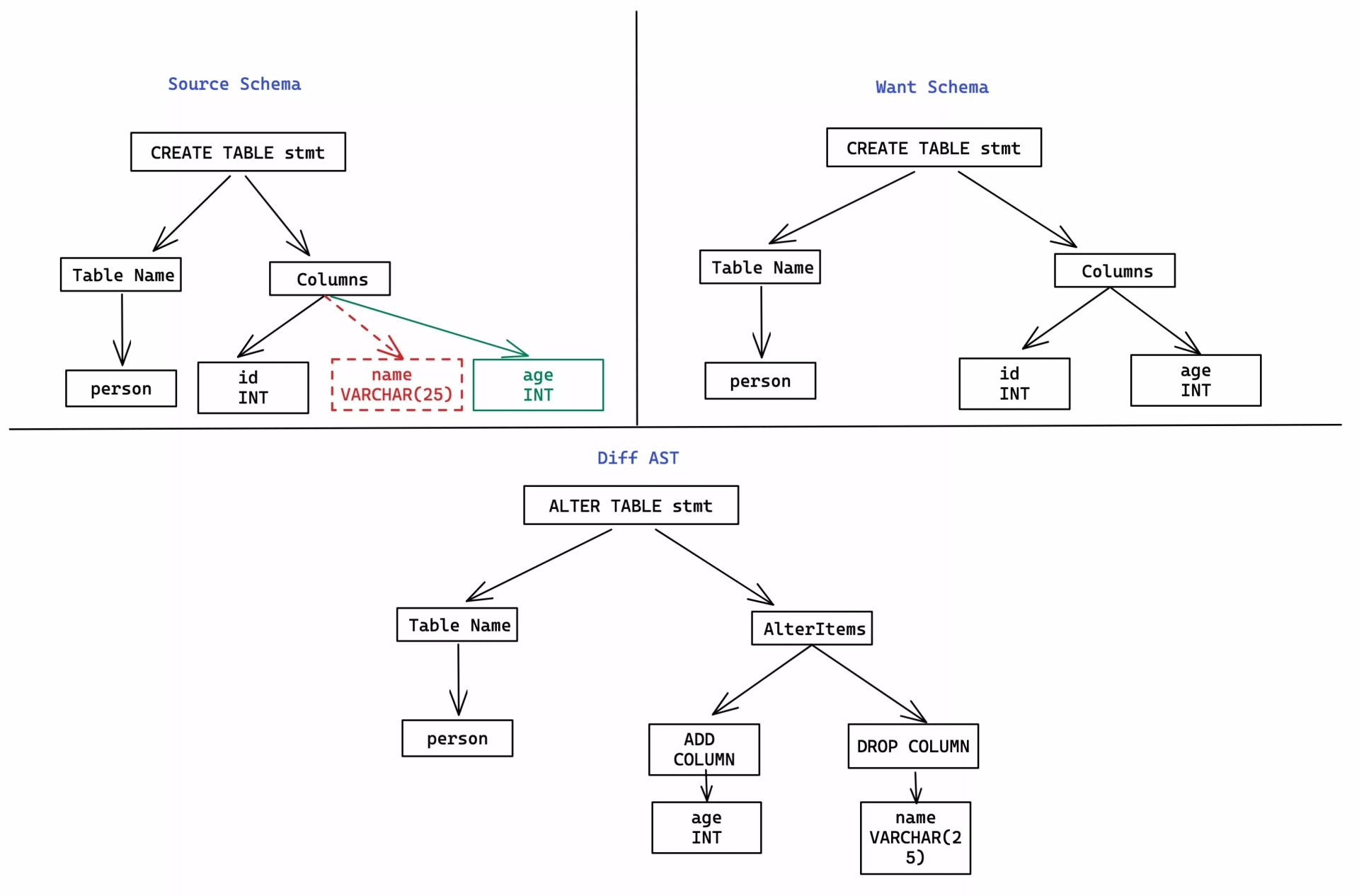
Diff on SQL AST
Bytebase then walks through the ASTs for both database schemas and compares two corresponding entities (which may not exist) from ASTs. The following chart shows a simple example:
Handle Dependencies
Objects and operations in a database have dependencies, such as the need to ensure that a table exists before adding a column. The following subsections show how Bytebase handles these dependencies.
Dependencies between different objects
There are many dependencies between database objects, like constraints depending on indices and columns, and columns depending on the table. We need to deal with them according to the topological order. The creating order must follow the below list, and the deleting order should follow the reverse order:
- Table
- Column
- View
- Index
- Constraint
Function, trigger, and procedure will not be validated at creation time, so we can create them anywhere after deleting the origin one.
Dependencies between different operation types
Also, we should sort dependencies among operation types. Below lists the order:
- New node creation, like adding a new column.
- In-place node updates, like changing an existing table definition.
- Deletion triggered destruction node updates. Because we cannot update some nodes in-place like indexes, we should drop the original one and create the new one instead.
- Addition triggered destructive node updates.
- Node deletion.
Deparse
Finally, we get the processed ASTs, we convert them back to SQLs.
Recap
- Convert SQLs to ASTs.
- Compare the ASTs to generate diff result AST nodes.
- Adjust the ordering of result AST nodes to keep safe orders.
- Convert diff result AST nodes to SQLs.
Learn more
You can follow docs to learn more about using synchronizing schema.


