You can't protect data you haven't found. Before you mask it, encrypt it, or gate access to it, you first have to know which columns hold the PII, PHI, and other regulated stuff. That's sensitive data discovery, and it's the unglamorous step everyone skips until an auditor asks.
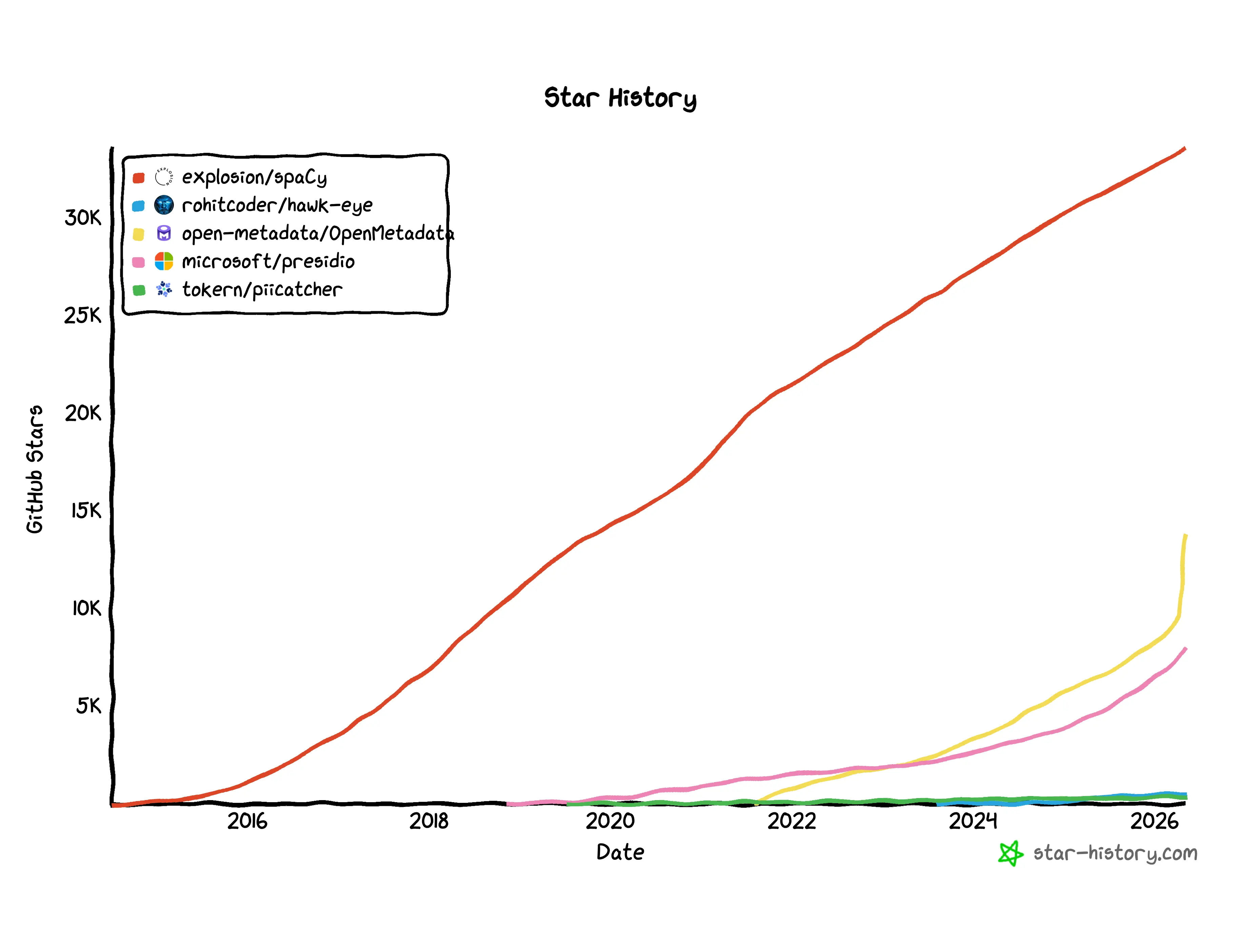
The open source options span a wide spectrum, and they don't all do the same job. On one end you have low-level NLP building blocks. In the middle, PII libraries with batteries included and CLI scanners that crawl databases and storage. On the far end, full metadata platforms where classification is one feature among dozens. The five below cover that range. One of them (PiiCatcher) got archived in January 2026 but still shows up in old guides, so I've kept it in the list with a clear warning rather than let you find out the hard way.
spaCy
spaCy is the NLP library that quietly powers half the tools on this page.

It provides named entity recognition (NER) for persons, organizations, locations, and other entities in text. PiiCatcher, OpenMetadata, and Microsoft Presidio all lean on spaCy under the hood. So spaCy isn't really a discovery tool you reach for directly. It's the engine the discovery tools are built on. Pick it when you're building a custom detection pipeline and want to start from the metal.
Microsoft Presidio
Microsoft Presidio is an actively maintained PII detection and anonymization library, and it's the one I'd point most teams at by default. It pairs spaCy NER with regex, rule-based recognizers, and checksums.
Detection is handled by 50+ predefined recognizers (credit cards, SSNs, phone numbers, names, locations, financial data, bitcoin wallets) plus whatever custom recognizers you add. It covers text and DICOM/standard images, multi-language, with context-aware confidence scoring.
The catch: there's no native database scanner. You sample rows yourself, hand them to Presidio, and tag the results yourself. The upside is the separate Anonymizer module, which can mask, redact, hash, or encrypt findings in the same pipeline. So you detect and remediate without leaving the library.
Verdict: the safe pick for teams building their own discovery pipeline, especially when you're scanning text fields, log streams, or document corpora alongside databases. You bring the plumbing, Presidio brings the brains.
Hawk-Eye
Hawk-Eye is the broad-spectrum scanner of the bunch, covering databases, cloud storage, and files, including images and videos via OCR.
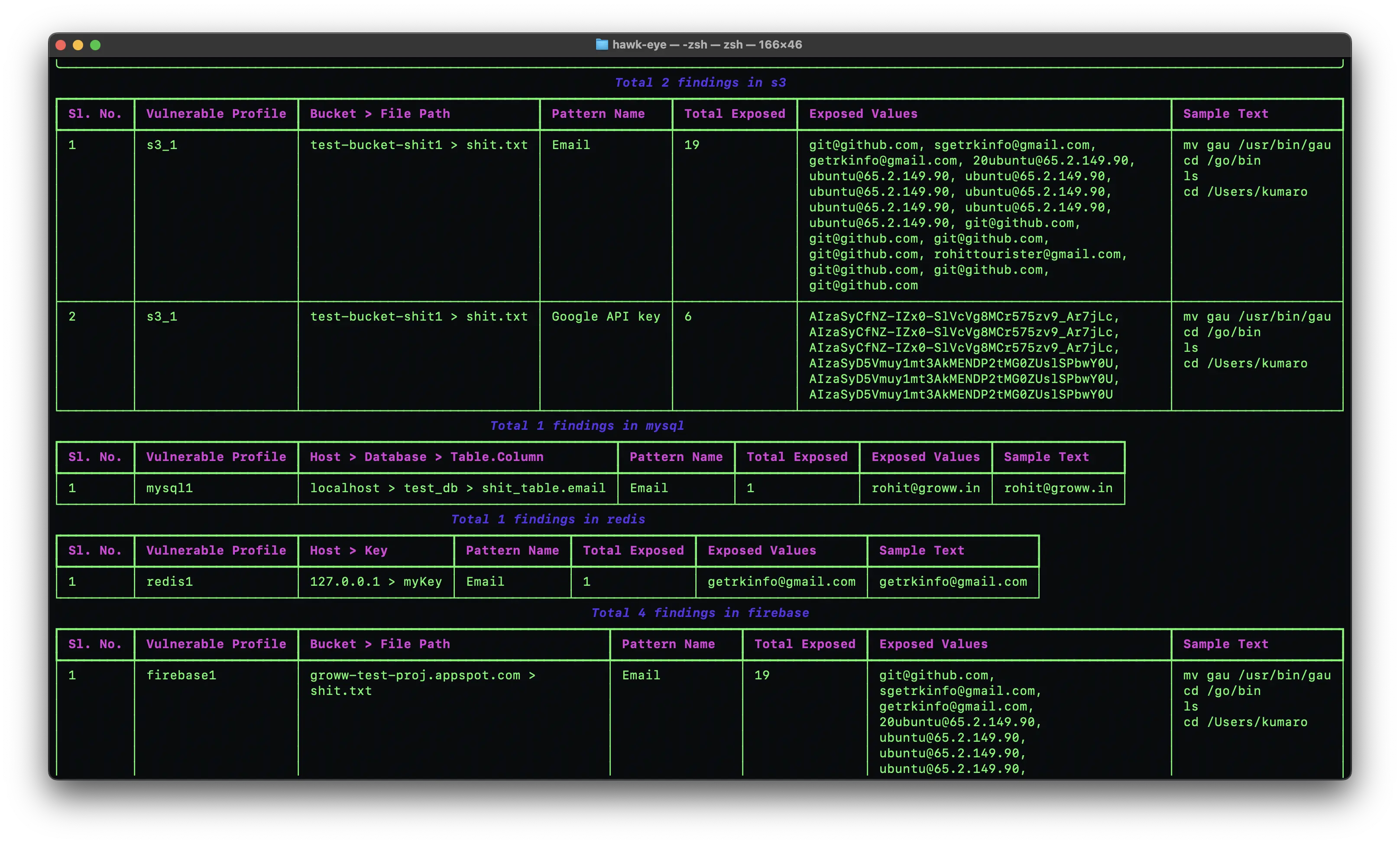
It does pattern matching with configurable fingerprints in YAML, and runs OCR across 350+ file types including DOCX, PDF, images, and videos. On the data source side it reaches MySQL, PostgreSQL, MongoDB, CouchDB, Redis, S3, Google Cloud Storage, Firebase, Slack, Google Drive, and the local filesystem.
The whole point here is coverage. A database scanner stops at the database, but PII rarely stays put. It leaks into a Slack thread, a CSV in S3, a screenshot in someone's Drive. Hawk-Eye follows it there.
Verdict: reach for it when the security team needs to audit data sources well beyond the database.
PiiCatcher (archived)
PiiCatcher was archived in January 2026 and is now read-only on GitHub. No new releases since v0.21.2 (July 2023). It still runs, but bug fixes and security patches will not land. New deployments should use Microsoft Presidio (above) or one of the platform options below.
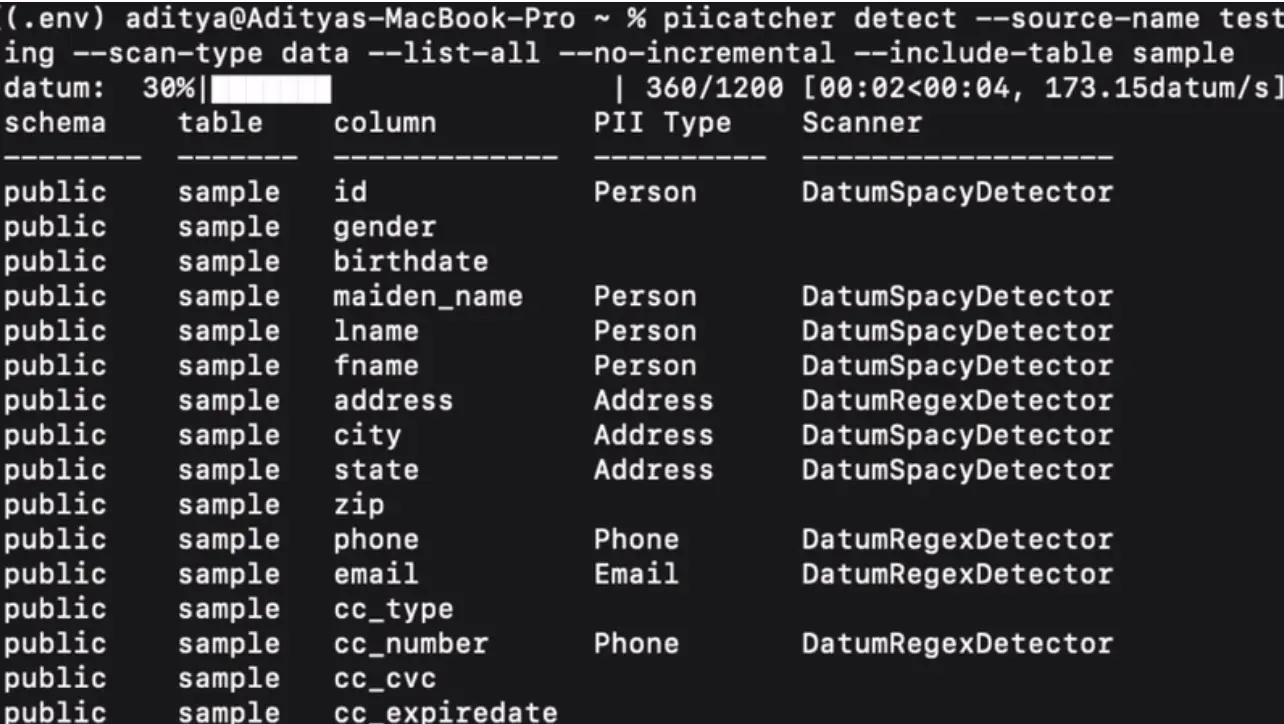
For context, PiiCatcher was a focused CLI scanner that detected PII in databases (PostgreSQL, MySQL, SQLite, Redshift, Athena, Snowflake, BigQuery) using regex on column names plus spaCy NLP on sampled values, then tagged findings directly into DataHub or Amundsen. That catalog integration was its real strength, and to be honest nothing has stepped in to fill that exact niche. Hawk-Eye covers a different database list (no warehouses), OpenMetadata wraps classification inside a full platform, and Presidio is a library, not a scanner. So if you loved PiiCatcher, none of these is a drop-in replacement. They each solve a slightly different shape of the problem.
OpenMetadata
OpenMetadata is a unified metadata platform that treats auto-classification as a core governance feature, not a bolt-on.
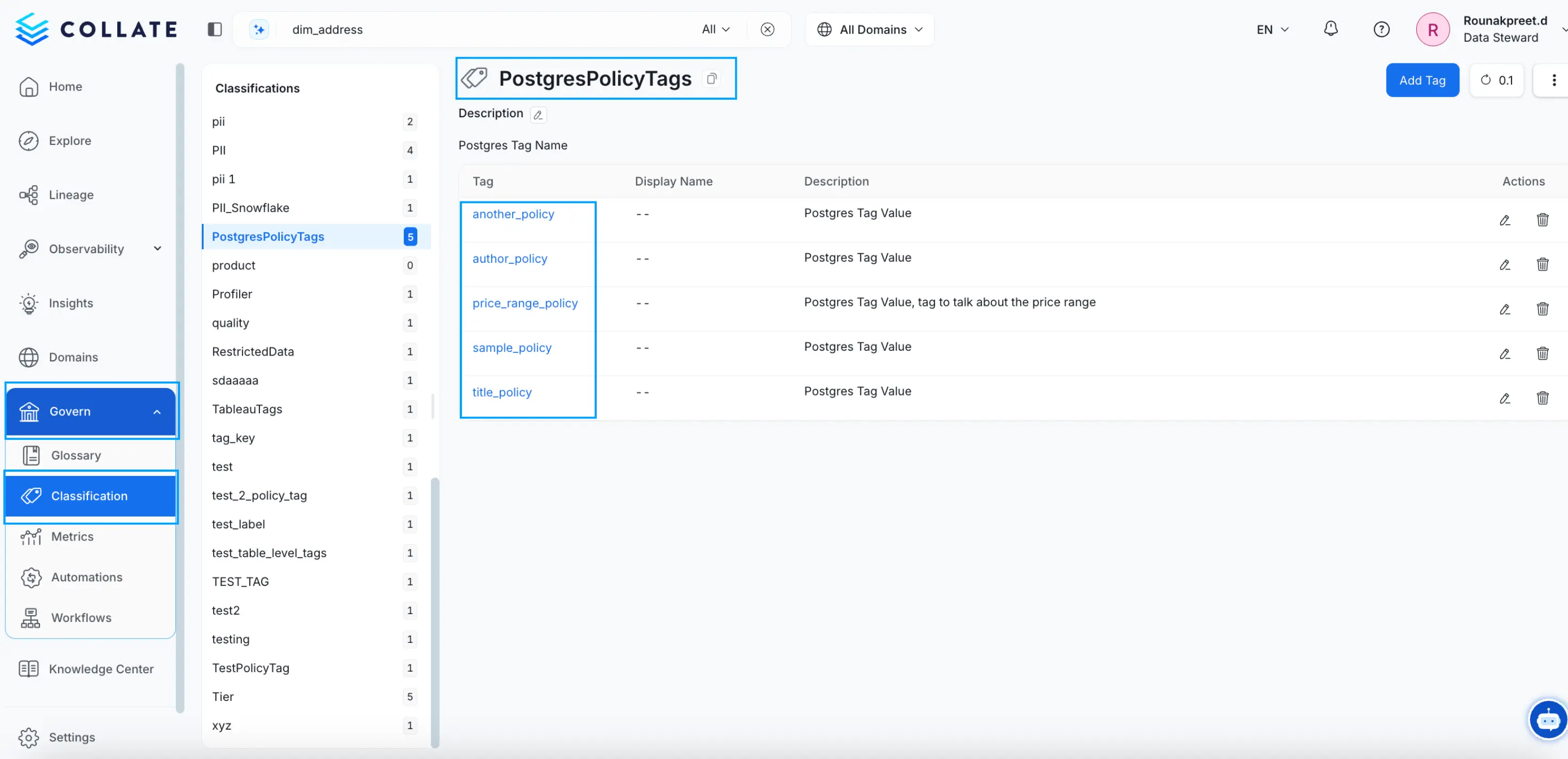
Its auto-classification workflow is powered by spaCy with configurable confidence thresholds (0 to 100). It identifies PII and either auto-applies tags or queues them for review. It runs as a separate workflow from metadata ingestion, so you tune classification independently. On reach, it ships 84+ connectors across databases, dashboards, messaging, and pipelines.
The reason to use OpenMetadata is what happens after classification. Tags don't just sit in an inventory, they drive data quality rules, access policies, and team workflows. And the no-code profiler puts classification within reach of people who aren't engineers.
Verdict: the right call when you want classification to actually drive downstream governance, not just produce a list nobody reads.
Alternative: DataHub is another open source metadata platform, but its auto-classification only supports Snowflake and is marked as deprecated. On DataHub, plan to wire up your own scanning, e.g. a Presidio-based job that writes tags via the DataHub API.
Comparison
| Tool | Status | Language | Primary use case | Detection method | Data source support | License |
|---|---|---|---|---|---|---|
| spaCy | Active | Python | NLP library / building block | Named entity recognition (NER), ML models | N/A (text processing only) | MIT |
| Presidio | Active | Python | PII library with built-in recognizers | NER (spaCy) + regex + rule-based + checksum | Text input (programmatic); no native DB scanner | MIT |
| Hawk-Eye | Active | Python | Multi-source scanner (DBs, cloud, files) | Pattern matching + OCR | MySQL, PostgreSQL, MongoDB, Redis, S3, GCS, Firebase, Slack | LGPL 2.1 + Commons Clause |
| PiiCatcher | Archived (2026) | Python | CLI scanner for databases | Regex + NLP (spaCy) | PostgreSQL, MySQL, SQLite, Redshift, Athena, Snowflake, BigQuery | Apache 2.0 |
| OpenMetadata | Active | Java / Python | Data platform with governance | Auto-classification workflow (spaCy), confidence thresholds | 84+ connectors | Apache 2.0 |
Picks by use case:
- spaCy for building a custom NER pipeline from scratch.
- Microsoft Presidio to drop in a maintained PII library with batteries included.
- Hawk-Eye for coverage across databases, cloud storage, and files.
- PiiCatcher, skip it for new work. The project is archived.
- OpenMetadata for classification inside a full metadata platform.
Start lightweight. Move to the full platforms when governance actually demands it, not before.
Discovery, then protection
Discovery is only the prerequisite. Once you know which columns hold sensitive data, the next step is controlling what's actually returned at query time. Bytebase dynamic data masking is driven by classification results: scan, classify, mask. The Bytebase REST/gRPC API takes classification output and applies masking policies, so a discovered PII column gets masked without a human in between.