First Encounter
The other day, I stumbled across motherduck.com. The website was rough.

While with an all-star team.

From its slogan "Data Infrastructure and Analytics" and the team background, I guessed they want to challenge Snowflake and/or Databricks. But how? Building yet another cloud-native warehouse with claimed performance/price benefits is meh. And MotherDuck is quite unusual name. Why would they choose it?
Today, after reading their funding post (together with an expected website redesign), I now have a better understanding to answer those questions.
Naming
The name MotherDuck comes from DuckDB, the SQLite for Analytics. MotherDuck commercializes the open-source DuckDB, which is a standard infra startup playbook nowadays.
Manifesto

I was confused by the serverless part at first. Though serverless is a much-abused word, most people would still pair serverless with cloud. MotherDuck markets itself as serverless, on the other hand, it says not to wait for the cloud, and then they probably would still offer a cloud service (who wouldn't?).
In common sense, serverless means there are still servers that are masked by the cloud service providers. Servers exist, users just don't need to care about them. While MotherDuck's serverless is a different thing, there is no server at all, apparently, since the underlying DuckDB is just a library to be embedded instead of a server on its own.
Democratizing Data
Snowflake brings the novel idea to separate the compute from storage, this architecture innovation grants it a huge competitive edge over the years. While from the product perspective, they are still tightly coupled since the data is locked in the Snowflake platform.
MotherDuck is different. Say you have a single data file, Parquet, CSV, SQLite or whatever format, that file resides on your local disk, S3, GitHub or anywhere. Then you use MotherDuck to mount that file from the computing environment of YOUR CHOICE, now you have a powerhouse ready to analyze that file. Because MotherDuck's zero dependency (thanks to SQLite-inspired DuckDB), it just takes seconds to acquire the MotherDuck binary (and even this will be eliminated after the pre-built distro includes it).
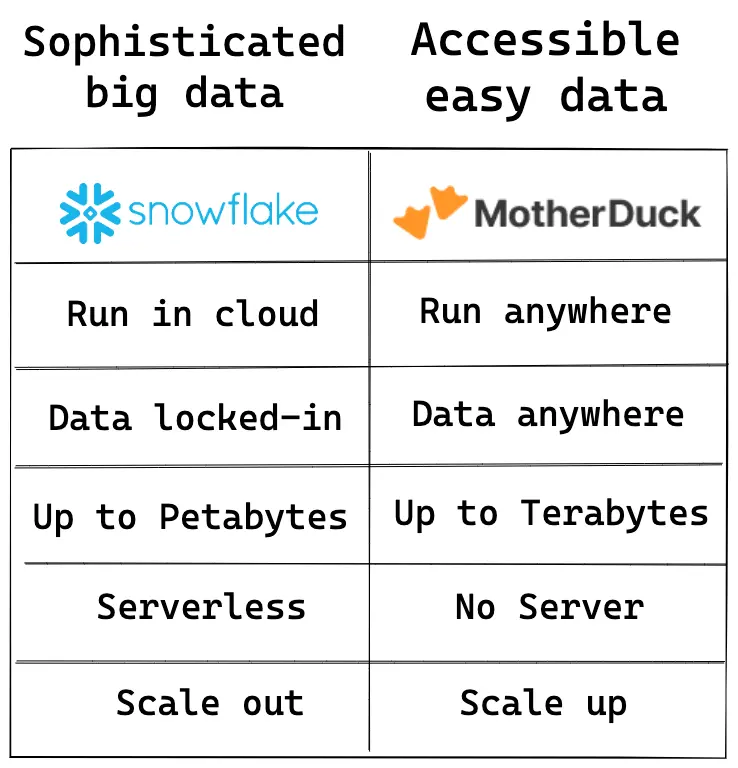
While Snowflake separates the compute from storage, MotherDuck taps the compute into the storage. With MotherDuck, as long as you can access the data file, you have the data powerhouse, and beyond that data powerhouse, you can build data solutions.
Take a real example, OSSInsight, a site to ingest GitHub events in real-time and offer insights. While its tech stack has already been simplified by adopting TiDB, the future MotherDuck could probably deliver a similar version with an even simpler stack.
Because with MotherDuck, all application runtime artifacts can be captured in a single file.
This is not a new idea though. The legendary Hypercard introduced this, to store a self-contained application and data into a single file.
Also, the long-standing FileMaker Pro, where the entire app and data are stored in a single .fmp12 file.
Yet MotherDuck could bring this idea to a new level, being capable of processing terabytes of data efficiently, defining open protocols among Dataset/MotherDuck Engine/MotherDuck Platform, integrating with GitHub to promote collaboration and etc.
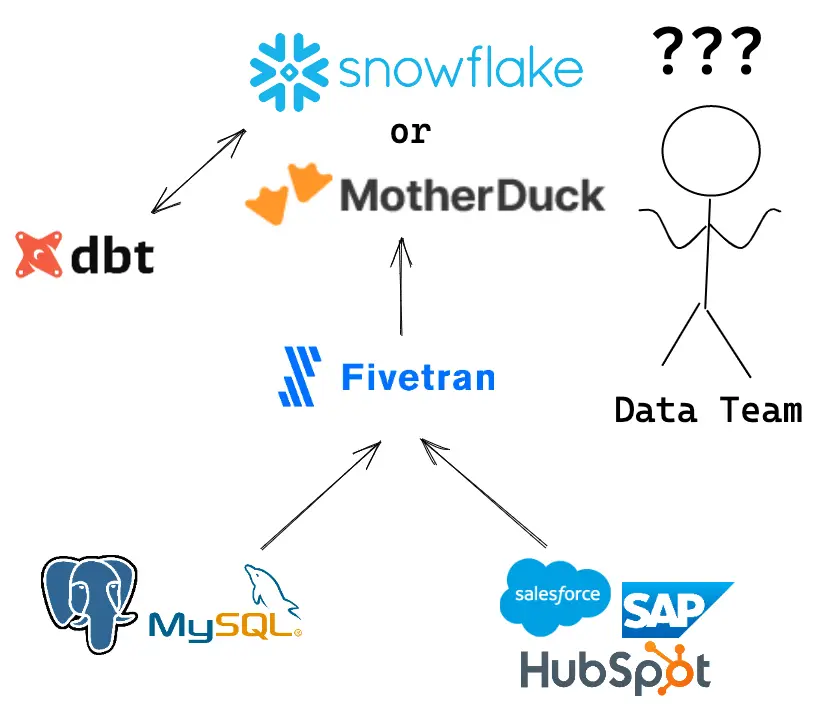
Immediately, MotherDuck starts competing with Snowflake on all fronts. Data teams still need Fivetran to move the data around, dbt to transform the data back and forth, even meltano to assemble the platform, but for every analytic task, they will have to decide where to run it from, the Snowflake Cloud or the whatever computing environment at hand with MotherDuck.
And in the long horizon, it's all uncharted. MotherDuck could unleash all kinds of new data solutions. Only sky is the limit.

MotherDuck's idea is novel, also the timing is perfect. The data analytics space is waiting for the next paradigm shift. While practitioners are content with better Snowflake alternatives, visionaries demand more. Instead of competing on the performance/cost frontier, MotherDuck chooses a different battleground, very wisely.
Parting Thought
People give away the data to Snowflake alike for the processing power. With MotherDuck, they can acquire similar processing power while still controlling the data themselves. They can keep the data wherever they want, share it with whoever they like, and use it whenever they need.
While Docker has become the runtime and standard to make applications universally accessible, MotherDuck could become the runtime and standard to make data universally accessible.
And this time, MotherDuck must be better prepared than Docker, Inc, to get the lion's share if the vision is realized. Good luck team MotherDuck and just wondering would Ducker make a better name :)