TL;DR
If you only need to remember three words: Sharding! Sharding! Sharding!
Reliability is a hard but important problem
The author has spent years in the past on building highly-available (HA) database services and service infrastructures at Google Cloud. It’s very important to build HA services to customers who bet their business success on the underlying infrastructures. Cloud customers might even build their own solutions on top of it to service their customers. Please show empathy to your customers who are angry or crying when unexpected events affect their services and business.
On the other hand, it’s extremely challenging to build such reliable Cloud services and infrastructures. Reliability is subjective, and availability is objective. One can never build a 100% available service because we can never guarantee humans or machines not to make mistakes. Industry uses a number of 9s to set the objection of service availability. Let’s take a look at numbers in the table below to get a sense of 9s.
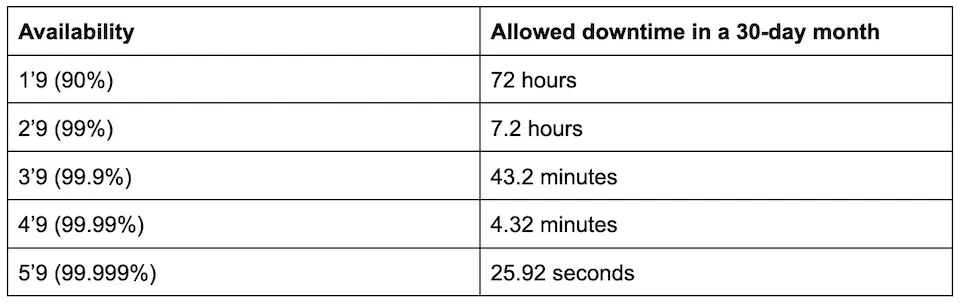
If someone has ever experienced an outage, it would be lucky to get service downtime within an hour based on past observation. It takes a lot of time to notice and declare an outage reported by customers or monitoring, escalate, root cause, find solutions, and mitigate. All these steps require interventions from multiple humans who are not as fast as programmed machines. Everyone get 2’9s, Oops!

Sharding
Wait a second. Aren’t we designing scalable distributed systems for supporting modern services? In CAP theorem, also named Brewer's theorem after computer scientist Eric Brewer (thanks Eric!), one can only achieve two out of three of Consistency, Availability, and Partition. For services that do need data consistency, why don’t we partition the system ourselves to achieve high availability. Let’s take a look at an example of a Serverless service running on a Kubernetes cluster consisting of a collection of machines.
The request can be retried with exponential backoff and handled by other live machines, if a machine or an instance of software goes down. Say if any machine would fail 43.2 minutes (3’9s) in a month, the application can achieve 9’9 availability surprisingly with three retries, i.e. 0.0026 second of downtime per month. If it were a single machine, retries will not help. Retries can result in long-tail latency. Well, if I want Pizza, regardless how much time it takes, I will find the next opening Pizza shop.
Serverless service architecture has also enabled progress rollouts described in the Google SRE Book service best practices. Most outages are caused by software or configuration updates as part of the rollouts. If we were able to experiment new updates in a single shard first, the damage will be scoped. If the downtime were T, the amortized downtime for the whole service would be T divided by N where N is the number of shards. For example, a shard of 2’9 availability with 10 shards can bring overall service availability to 3’9 if all downtime is triggered by rollouts.
Applying the same analogy, a global service can be sharded or partitioned into multiple clusters in multiple regions. When a cluster (equivalent to a machine above) fails due to lightning strike (yeah, it did happen to Google's data center), fire, earthquake, cable disconnection, the overall availability of a global service will be better than the one in a single cluster if there are multiple cluster shards.
Let's take a moment off and play an online game together. Fortnite time! Other than location based sharding, one can find other sharding methods based on user stories or product designs. For example, many online gaming services require users to pick a server when they register an account. This server is a virtual shard of the service. The user account and its user data are stored in the database belonging to the registered server. The servers are not necessarily located in different data centers but provide a means to update softwares or configurations server-by-server without impacting all users at the same time. One may be cautious how users from different servers collaborate such as having a 20-minute competition. Competitions can be further shard-ed and distributed to different servers in order to minimize the geographic distance and latency for participants in the competition. Software updates will wait for all competitions to complete on the server. You gotta believe my gaming addiction was really to research system designs :).
Shard management
I cannot manage so many of them any more. DevOps tools are certainly here to help address the growing complexity. For example, Kubernetes is an open source system for managing containerized applications across multiple hosts. Knative is a Kubernetes-based platform to deploy and manage modern Serverless workloads. Nowadays, it’s easier to manage the computing part of a service than ever before with these tools.

What about databases? Well, hum. A silence falls on the hall, till Bytebase comes to the show. Bytebase is an open source software offering a collaborative solution to help DBAs and Developers manage the lifecycle of application database schemas. Beyond that, it offers a Batch Database Management solution allowing DBAs and Developers to manage a collection of databases with identical schemas. We believe this solution can help to complete multiple gaps in the DevOps space including database sharding for building HA service.
 Screenshot for a Bytebase project in tenant mode. Four databases in the US, Asia, Europe, and Mars. And one database in the staging environment for testing before the change is applied to production.
Screenshot for a Bytebase project in tenant mode. Four databases in the US, Asia, Europe, and Mars. And one database in the staging environment for testing before the change is applied to production.
Closing
One may ask why not use a single instance of distributed, globally scalable SQL database service such as Cloud Spanner offered by Google. These solutions are great, however, running a global service with this solution only still has several limitations.
- We are seeing growing regulations around the world to restrict data storage. It’s a no-go for having a single instance of database for storing global user data regardless how amazing it is.
- Multi-region global databases would still have only one region to be read-writable. When network partition happens, writes from other read regions are halted. It’s still a great solution for some use cases though without customers implementing their own global data replication solutions. For example, global account registrations relying on writes are not as critical as many other use cases such as login authentications relying on reads.
In fact, Google Cloud services are moved to architectures with regional Spanner instances as an organizational effort of improving Cloud service reliability. It was a hugely difficult, very costly effort taking years to happen. You should consider architecting your systems with sharding strategy on day one if possible.