Market Cooling Down
2021 was the most active year for database financing in history, and the trend continued in the first half of 2022 with companies such as Timescale, Dbt Labs, Starburst, DataStax, and SingleStore all completing financing rounds worth more than $100 million. However, as the macro environment deteriorated, no mid-to-late-stage database companies completed financing events in the second half of the year.
In terms of early-stage projects, it is worth mentioning the $30 million financing of Neon and the $47.5 million financing of MotherDuck, both of which had all-star founding teams and went straight to Series A.
At the end of the year, MariaDB went public through SPAC and immediately fell from $11 to just over $3 (the article was written in Jan, now it's trading below $1). Its stock price performance reflects the trend of the database financing market this year: a peak at the beginning, followed by a steady decline. Although the financing environment is not as favorable as before, the database industry has shown more highlights compared to the previous year.
Technology of the Year - Velox
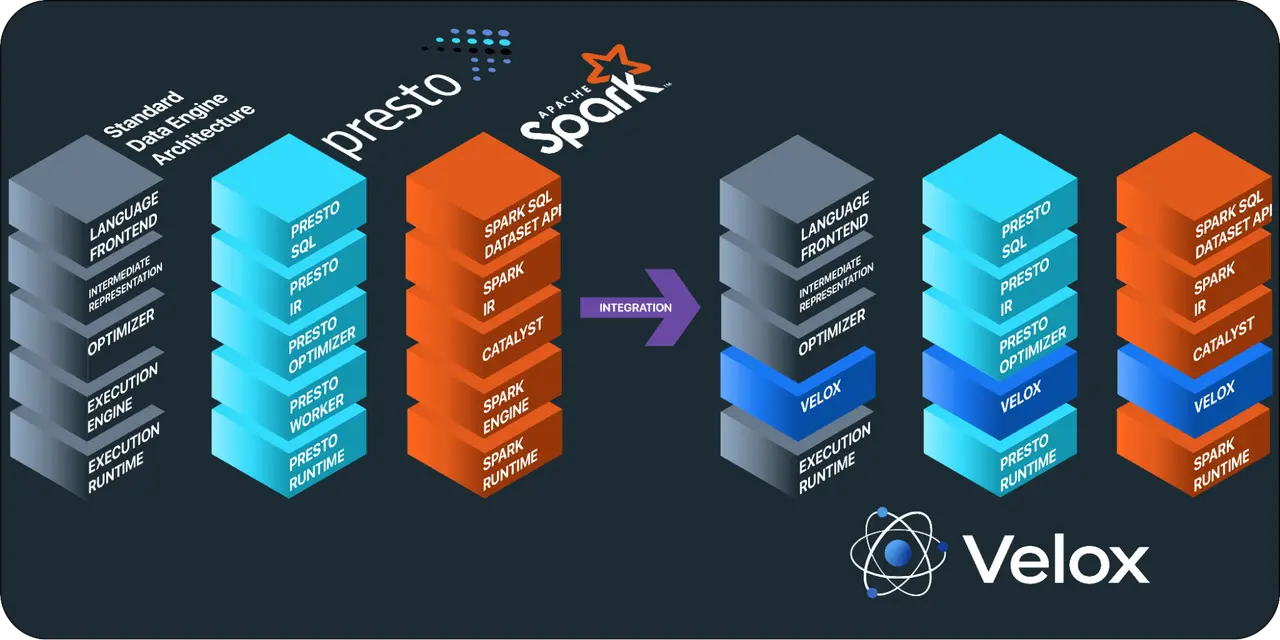
Every database requires an Execution Engine, which was previously developed separately by different database systems, such as Presto and Spark. However, the functionalities that these Execution Engines must provide are all similar. Velox has extracted these common capabilities and packaged them into a library, including the following main components:
- Type - a universal type system
- Vector - vectorized capabilities based on the Apache Arrow columnar memory format
- Expression Eval - expression evaluation, including the use of vectorized capabilities mentioned above Function - a function framework
- Operators - operators, such as TableScan (full table scan), Project (mapping), Filter (filtering), Aggregation (aggregation), Order (sorting), and Join (joining) in SQL databases
- IO - integration with IO systems
- Resource Management - management of computing resources
As an Execution Engine, Velox prioritizes execution efficiency and engineering velocity, and thus adopts C++ as its implementation language. In fact, Velox can be thought of as the C++ STL library in the database engine, which, like the STL library for C++, has a milestone significance for the database engine.
To understand this point, we need to look at the architecture of the database engine. The process of handling a query is roughly Language Frontend -> IR -> Optimizer -> Execution Engine -> Execution Runtime. Language Frontend + IR has already been standardized to SQL, and the frontend of the database engine has been mostly standardized as SQL dialects have gradually converged towards PostgreSQL. Once Velox standardizes the Execution Engine, the remaining differences will be in the Optimizer and Execution Runtime, which are the true differentiating points between engines.
The closest thing in the physical world to a database is probably F1, so let's use F1 as an analogy.

Language Frontend + IR is equivalent to a set of driving instructions; Optimizer is equivalent to strategies, such as whether to stop twice or three times at a pit stop and whether to use dry or wet tires; Execution Engine is equivalent to the entire transmission system, including the body material, gears, wings, and drive shaft; Execution Runtime is equivalent to the tuning of suspension stiffness and gear ratios; different F1 racetracks and weather conditions represent different business requirements.

With the standardized Velox, it is as if everyone is using the same car parts. Developing a database engine is like simplifying the competition in F1 racing into "strategy (Optimizer) + tuning (Execution Runtime)" and adapting to "racetracks + weather (business scenarios)." The result is that each team pushes hard on the first two parts, and the fastest lap times on each track are constantly being broken.
Of course, the mainstream databases on the market all have their own Execution Engines, so the likelihood of replacing them with Velox is not high. However, new database projects are likely to adopt Velox. With Velox, adding vector capabilities to a database can be done in just a few weeks, just as a racing team does not need to conduct wind tunnel tests to develop wings, but only needs to figure out how to install existing wings in the right place.
Feature of the Year - ReadySet
ReadySet is a company founded by Jon Gjengset based on his doctoral thesis at MIT, Partial State in Dataflow-Based Materialized Views. In simple terms, ReadySet provides a caching layer, but unlike specialized caching databases like Redis, ReadySet is compatible with the MySQL/PostgreSQL protocol. For applications, this means that it is completely transparent, and ReadySet can be seen as a part of MySQL/PostgreSQL itself. With ReadySet, applications no longer need to write additional cache processing logic, which is a significant advantage. ReadySet solves one of the two major challenges in computer science, cache invalidation (although not entirely, it can cover about 95% scenarios).

Although ReadySet is an independent product, it is more appropriate to classify it as a feature of a database based on its form. In fact, PlanetScale has likely borrowed the idea from ReadySet and added the PlanetScale Boost feature to its own database offering.

There is a wealth of information available on ReadySet, and the code for ReadySet is open source and available on GitHub. For technical individuals who want to quickly understand the implementation, How PlanetScale Boost serves your SQL queries instantly is a good read.
For non-technical individuals, the analogy provided in the appendix of Jon's doctoral thesis can also provide a general understanding of the concept.
ReadySet is a recent success story of academic research being translated into industrial applications. It is likely that other databases will adopt this technology in the future.
Database of the Year - Neon

From a product perspective, Neon is the PostgreSQL version of PlanetScale. Like PlanetScale, it open-sources its engine and focuses on Serverless and Developer Workflow. However, from a technical perspective, Neon adopts a more modern architecture. Its storage engine has been designed with features such as Branching in mind, which is also a key differentiating point of the product and is prominently featured on its website.
Another highlight of Neon is its user-friendly experience, among all the database serivce I have tried, Neon costs the least amount of time to connect.
Databases based on distributed middleware, such as PlanetScale, may still have compatibility issues with native MySQL. However, Neon's storage and compute separation architecture completely eliminates this issue, as the Server layer directly uses PostgreSQL's native Server layer. Another advantage of Neon is that it is based on PostgreSQL, which makes it more feature-rich and enterprise appearing. Although Neon currently targets TP scenarios, its architecture, combined with PostgreSQL's scalability, also has potential for expansion into AP and timeseries databases.
Other Databases
Google AlloyDB
This year, Google Cloud released AlloyDB, which is also based on the PostgreSQL protocol. Like Aurora and Neon, AlloyDB adopts a WAL-based storage and compute separation architecture. However, instead of focusing on Developer Workflow like Neon, AlloyDB prioritizes AP capabilities on top of its TP foundation. While AP scenarios are more extensive, there are already several HTAP databases on the market, and AlloyDB is closed source, which is why our Database of the Year was given to the more innovative and open-sourced Neon.
Before the release of AlloyDB, Google Cloud had a product line of TP/AP databases, which included:
- Vanilla OLTP databases MySQL, PostgreSQL, SQL Server - Cloud SQL.
- Cloud-native OLAP data warehouse - BigQuery.
- Cloud-native distributed OLTP database - Cloud Spanner.
AlloyDB is 3 in 1, as its name Alloy suggests.
Snowflake Unistore

The king of cloud-native data warehouses has also entered the HTAP race. Previous companies have entered the AP segment from the TP segement, but Snowflake is the first database to enter the TP market from the AP market. Snowflake has several advantages when it comes to HTAP:
-
Distribution.
-
Strong existing product and platform.
-
More potential high budget customers. Companies using Snowflake are ususally more affordable.
Overall, Snowflake's strengths make it a strong contender in the HTAP market.
However, transitioning from AP to TP also presents challenges:
-
Department boundary - Companies typically start with TP systems and then introduce AP systems as their business scales. It can be challenging to convince the development team or DBAs to use a database that is primarily designed for data warehousing to manage online business, especially considering the high cost of Snowflake.
-
It is also difficult to switch to a different TP system later on, as TP systems are upstream of AP systems and more mission critical. TP systems are online systems, while AP systems are offline systems (with a few exceptions for reverse ETL), so switching to a different TP system is like changing the engine of a plane in flight. It is usually the big data team that advocates for TP systems to switch to Unistore. However, from the perspective of the TP team, there is much less incentive to convince them to switch to Unistore.
Therefore, for an organization, before envisioning the productivity improvements that Unistore can bring, it is necessary to evaluate whether there is a supporting organization structure. Ideally, the combination of AP and TP data in Unistore can make data more accessible between organizations. However, in reality, it is likely that:
-
TP database teams may be reluctant to adopt Unistore, which is an AP/TP hybrid system (just like AP teams may be reluctant to adopt TP hybrid systems).
-
AP teams may use Unistore to expand into TP scenarios, leading to conflicts with TP teams and redundant development efforts.

SQLite
If you just glanced at Dr. Richard Hipp's 2022 Recap, you might think it was a relatively ordinary year for SQLite.
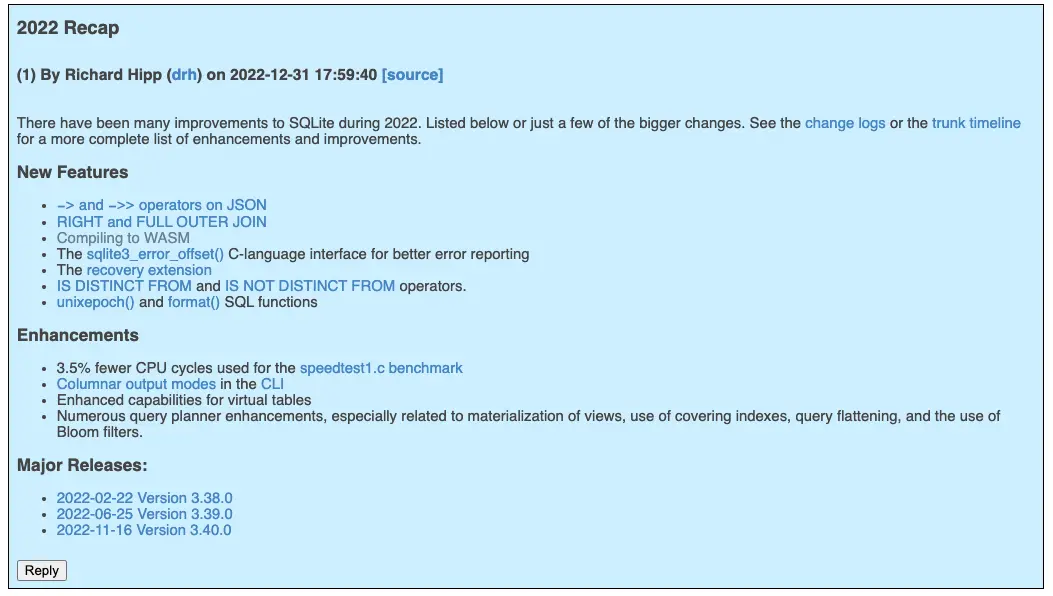
In fact, in 2022, the SQLite ecosystem took another big step forward, with the biggest development being that SQLite WASM became an official project within the community.

On the commercial side, Cloudflare launched D1, a service based on SQLite which is used in conjunction with its Cloudflare Worker.

Ben Johnson, the author of Litestream, joined fly.io and subsequently launched an open source project called LiteFS.

LiteFS is a FUSE-based file system designed specifically for SQLite. With LiteFS, it only takes 10 minutes to set up a globally distributed SQLite system.
In 2022, DuckDB, an AP version of SQLite, also experienced rapid growth.
MotherDuck, a commercial company based on DuckDB, gathered an all-star team and managed to secure a $47.5 million investment at the end of 2022, despite the challenging environment.

Looking forward, the evolution of SQLite technology may follow this path:
- SQLite + WASM: SQLite in your browser (2022)
- SQLite + WASM + LiteFS: Globally distributed SQLite in your browser (2023)
- SQLite + WASM + LiteFS + DuckDB: Globally distributed HTAP in your browser (2023/2024)
As the foundation continues to evolve, the industry will also explore killer solutions. Our MotherDuck: From SQLite to the Data Docker suggested that MotherDuck could become the Docker of data. The Datasette project has already demonstrated the potential in this area.
PostgreSQL
Although PostgreSQL dropped one spot in the annual ranking by DB-Engines in 2022, ranking behind Snowflake and BigQuery in third place, it remains the top-performing open-source database. In addition, PostgreSQL was voted the most loved database in the annual Stack Overflow developer survey.
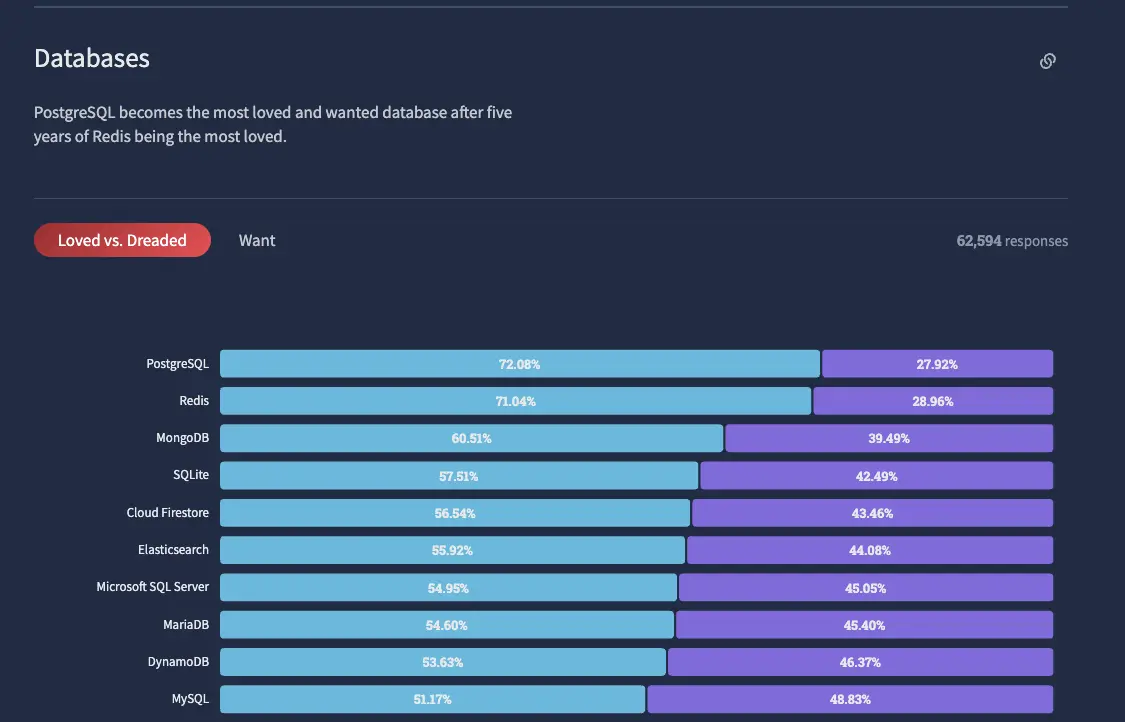
Furthermore, among professional developers, PostgreSQL slightly surpassed MySQL in popularity this year.
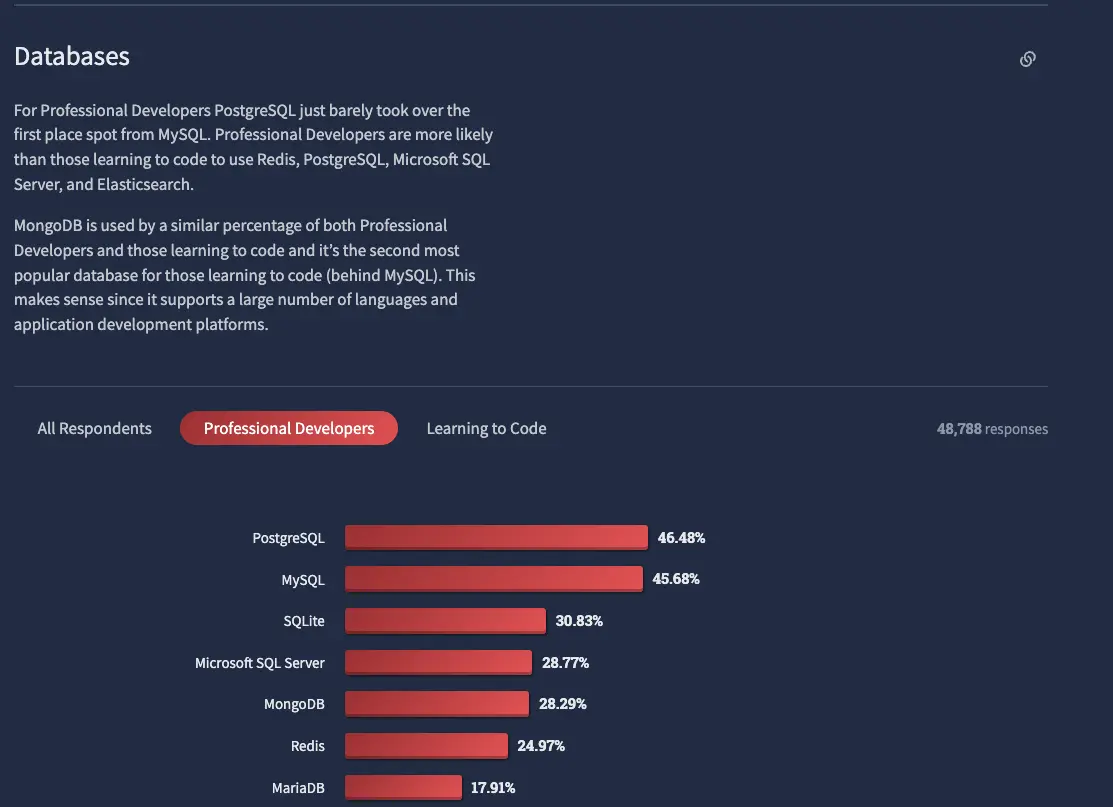
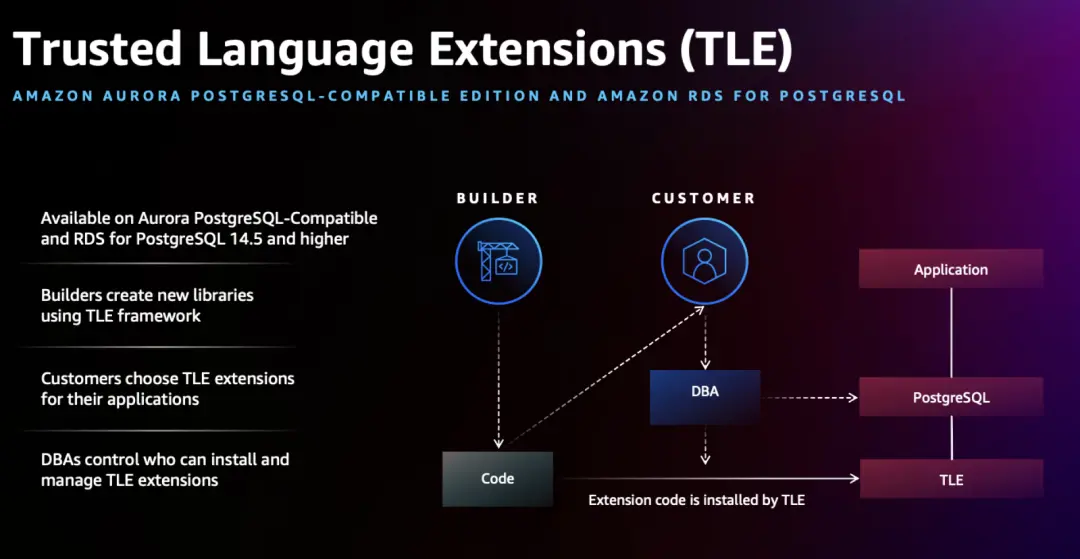
The aforementioned AlloyDB and Neon are part of the PostgreSQL ecosystem. Even Snowflake's syntax is largely derived from PostgreSQL. In addition, PaaS platforms like Supabase, Render, fly.io, bit.io that offer PostgreSQL services continue to thrive, and AWS also launched Trusted Language Extensions (TLE) for PostgreSQL at re:Invent.
It's the same PostgreSQL formula discussed last year:
PostgreSQL = MySQL + Geospatial + Multi-tenancy + Poor man version of (ClickHouse + MongoDB + Elasticsearch + InfluxDB)
PostgreSQL has an excellent architecture, rigorous code, and an independent yet active community, and time is on PostgreSQL's side. Just hope the 64-bit XID proposed in 2017 can be merged into the main branch sooner rather than later 🫠.

Industry Trend
Application Developers
In 2021, PlanetScale pivoted from hosting databases with Vitess to targeting application developers with a focus on developer workflows. In 2022, PlanetScale continued to make strides in this direction by releasing tools such as Revert and Boost.
And this year PlanetScale has found a spiritual partner Neon, which also focuses on developer workflows. The two companies' manifestos are quite similar.

The main difference between PlanetScale and Neon is MySQL-based vs PostgreSQL-based . It seems that the love-hate relationship between MySQL and PostgreSQL will never end. From native MySQL vs PostgreSQL, to distributed TiDB vs CockroachDB, to cloud-native AWS Aurora vs GCP AlloyDB, and now with the focus on developer workflows in PlanetScale vs Neon.
Check out PlanetScale vs. Neon for a comprehensive comparison.
Tooling
In 2022, the most significant release in the data category at AWS re:Invent was not a database but rather DataZone - a data management service that enables users to catalog, discover, share, and govern data.

As database engine functionality becomes increasingly powerful and the entire data stack becomes more complex, better steering wheels, navigation systems, and brake pedals are needed to control them. Database engine vendors have a tradition of acquiring database client tools, such as MongoDB's acquisition of Compass, Databricks' acquisition of Redash, and ClickHouse's acquisition of Arctype in 2022. However, as a whole, there is still a lack of comprehensive tools like Oracle Enterprise Manager, SQL Developer, and SQL Server Management Studio.
Convergence
Convergence reduces the delays and inconsistencies caused by data synchronization in heterogeneous systems and breaks down data silos. In the most ideal situation, a change in the initiating TP database can be reflected in CI run reports, and even evaluate the impact of reverse-ETL pipeline on itself, like throwing a boomerang that can circle back to your hand after a round.
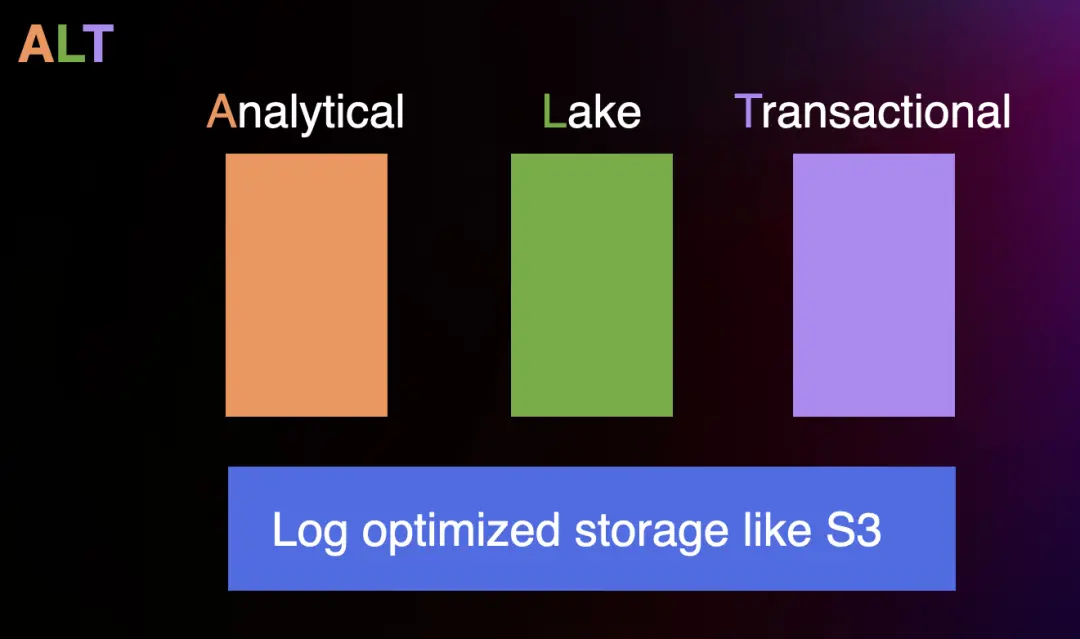
Database technology is converging, with a unified SQL language, execution engine, and log-based storage, allowing database engines to handle different scenarios within a grand framework. As mentioned earlier, PostgreSQL can already support various business scenarios through plugins. On the cloud, we have seen HTAP with AP + TP and integrated lakehouse with AP + Lake. Will the convergence of these three into ALT be far away?
AI + ChatGPT
Around 2019, Oracle was pushing the concept of Autonomous Database, and I read a lot of related academic papers and product information. My conclusion was that the concept was not yet mature. From a market perspective, AI can create many good stories, but even today, I remain skeptical about the practical application of AI in the database engine layer. Engineering capabilities rather than AI capabilities are still the bottleneck for solving current database pain points:
-
How to implement a solid cloud-native, serverless architecture, with separated storage and computing, spot instances, tiered storage, to provide cost-effective database services for multi-tenants?
-
How to combine TP, AP, and even data lake technologies together?
-
How to make the database change development workflow more similar to the code change development workflow?
Using technologies like GPT-3, it is possible to quickly generate SQL statements through natural language, which is a significant improvement over the limited natural language capabilities of AppleScript in the past. However, there is still a long way to go from generating approximate results in conversational scenarios to deterministic results in scenarios required by the optimizer.
Instead of creating an AI database, it may be more practical to create a database that better serves AI scenarios. This involves connecting the entire data chain from TP, AP, Lake, ETL, to reverse-ETL, relying on platforms like DataZone to govern the data, and extending SQL syntax to easily use AI/ML capabilities.
Scoring for 2022 Prediction
Let's review our last year's prediction
PlanetScale will be widely adopted, Vercel + PlanetScale, the VP stack will bring a new paradigm shift to the developer workflow, especially to attract a lot of front-end and full-stack developers.
50% accurate. PlanetScale has made good progress, but overall it has not achieved the degree of sweeping developers and bringing about a paradigm shift. By comparison, the combination of Vercel and Neon is also more promising.
There will be a new database coming out, and the main selling point will be developer workflow.
100% accurate. The aforementioned Neon and the recently launched Xata both focus on development workflow.
There will be startups building ClickHouse tools, and receive a lot of funding.
50% accurate. There were no new startups in this space, but ClickHouse Inc. did acquire Arctype as their client tool.
Firebolt will be the fastest-funded database company ever.
0% accurate. Couldn't be more wrong.
There will be killer solution based on SQLite.
30% accurate. Cloudflare D1, LiteFS, and official SQLite WASM are all highlights, but we are still waiting for a killer solution.
There will be an open source tool built for application database development.
20%. Bytebase own KPI, we made some noise. Yet, it's still a long way to go to become the de-facto tool for application database development.
35.7% overall accuracy, not bad considering the drastic macro environment shift.
2023 Prediction
-
OpenAI's technology will integrate with Microsoft's SQL Server and Power BI. Regardless of the degree of integration, it will be emphasized in product promotion.
-
Snowflake will launch its own BI product and may also make acquisitions in the BI field.
-
Snowflake Unistore goes further by expanding to the Data Lake. From Hybrid Table to Hyper Table? Hopefully, TimescaleDB doesn't mind 🙃.
-
Fly.io will release Globally Distributed SQLite in your Browser.
-
The top three in DB-Engine's annual ranking are 1) Snowflake, 2) PostgreSQL, and 3) SQLite. Given Snowflake's leading advantage from last year, there is no doubt in it being first place this year, so let's guess the top three.
-
A new database will be launched, with a focus on handling AI/ML scenarios and using the PostgreSQL protocol.
-
A tool will emerge for database application development scenarios. Go Bytebase 💪.
Parting Words
Grey Wolf and White Deer are two ancestral figures in Mongolian mythology, symbolizing expansionist ambition and strong life force, respectively. Expansion and survival will also be the themes for database companies in the next few years. On one hand, database technologies are converging, and vendors are easy to venture into each other's areas, with big players swallowing up smaller players. On the other hand, companies are competing fiercely in the database race while navigating the current economic cycle.
And compared to the saturated database engine market, there is more room for the database tooling market. Public cloud giants need to offer services like DataZone to connect the entire data product lines, while database vendors need to create their own database IDEs to provide a one-stop experience. Products like Bytebase allow teams to have a unified database development process to perform various database development activities across different clouds and database types.
From the handful System R developed 50 years ago to run on IBM mainframes, to the billions of SQLite instances running on various apps and IoT devices today, databases have always been moving forward, despite several economic cycles. We look forward to seeing more breakthrough combined with business innovations in 2023.
See you in 2024!
This article was originally written in Jan 2023. You can also read last year's review - Database Review 2021.