
A series of articles about database migration / schema change:
- What is a Database Schema?
- What is a Database Schema Migration?
- How to Handle Database Migration / Schema Change? (this one)
- Top Database Schema Change Tools in 2023
I recently noticed this post in Reddit's r/golang entitled "How do you handle migrations ?" It got 40+ replies in less than a day.
What is a Database Schema Change
A database schema is the structure of a database, which describes the relationships between the different tables and fields in the database. A database schema change, also known as schema migration, or simply migration refers to any alteration to this structure, such as adding a new table, modifying the data type of a field, or changing the relationships between tables.
Database schema changes are typically necessary when a database needs to be updated to support new features or functionality, or to improve system performance or security. In some cases, schema changes may also be required to fix bugs or other issues with the database.
Database Schema Change Challenges
Making a schema change can be a complex and risky process, as it can affect the entire database and any applications or processes that rely on the database. Therefore, it's important to carefully plan and execute schema changes to minimize the risk of errors or data loss.
Developers can't avoid schema change because products need to iterate. Adding new features often means modifying database structure, such as adding a new field to save new information, which involves database schema changes.
Let's take a look at the concerns raised by that reddit poster:
Lack of visibility of changes
The developer or the DBA may connect directly to the database and execute the change, and only the person knows what statement was executed and when it was executed (or they might just forget).
Ensuring the uniqueness and exclusivity of changes
An app usually has multiple deployments, but all connected to the same database. From the description, it appears that the author was trying to update the database when a new version deploys. So the question is, when multiple copies of the new version are deployed at the same time, how exactly to guarantee that only one of the copies can make changes to the database while the others wait?
Common Database Schema Change Mistakes
-
Failing to plan the change: Before making any changes to the database schema, it's important to carefully plan the change and make sure it won't cause any problems or data loss. This includes identifying any potential conflicts with existing data or applications, and determining the best approach for making the change.
-
Not testing the change: It's a good idea to test the change in a development environment before applying it to the production database. This will allow you to see if the change works as expected and identify any potential issues before they affect your live systems.
-
Not using a database migration tool: Many database systems have tools that can help you manage schema changes. These tools can automate the process of applying the changes to the database, which can help reduce the risk of errors and make the process more efficient.
-
Not communicating with your team: It's important to keep your team informed about the changes you're making to the database schema. This will ensure that everyone is aware of the changes and can take the necessary steps to update any applications or processes that depend on the database.
-
Not creating a backup: Before making any changes to the database schema, it's essential to create a full backup of the database. This will allow you to restore the database to a previous state if something goes wrong.
Best Practice to Make Schema Changes
As both the challenges and mistakes present, teams are eager to develop best practice to tackle this. That reddit poster ends up asking for best practices and tools that can be used in a production environment. From a best practice perspective, there are 2 main points:
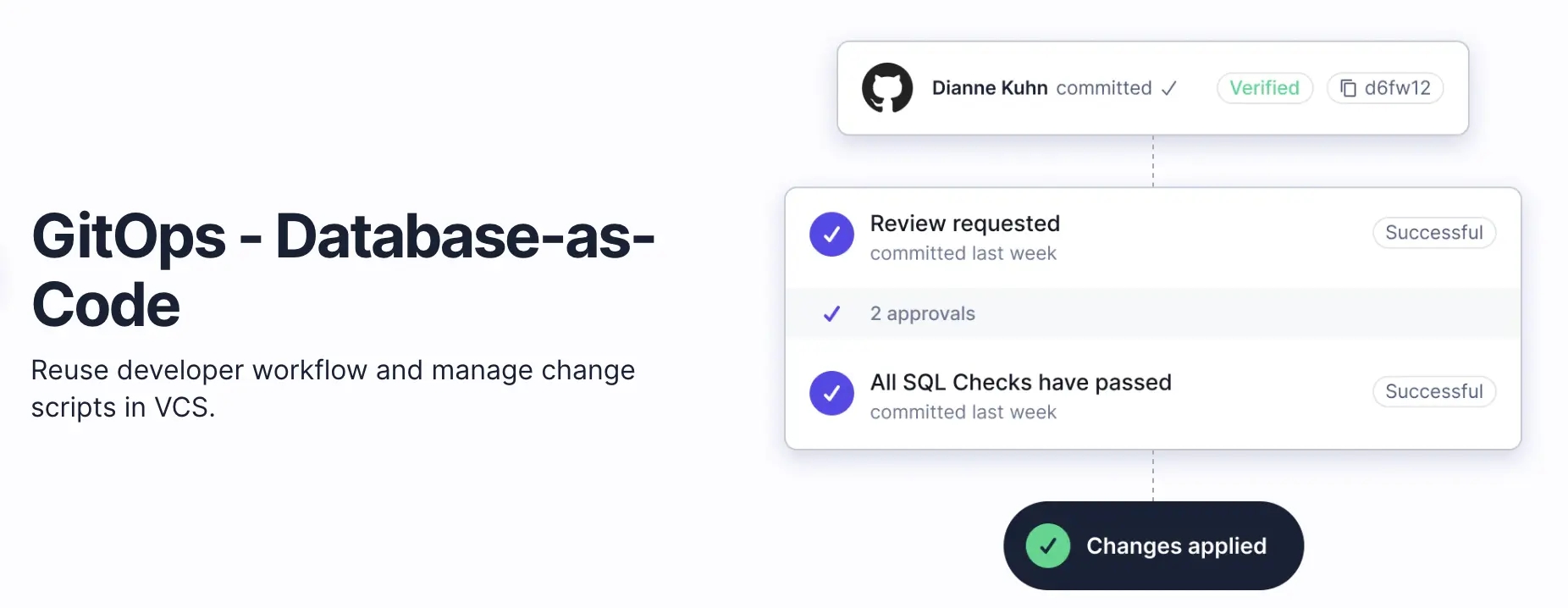
Treat your database changes the same way you treat code changes
Let's look at a typical code change CI/CD process:
- A change request is submitted to a code repository, such as GitLab (Merge Request, MR) or GitHub (Pull Request, PR).
- Say you've enabled some sort of CI actions, the MR / PR will first go through a series of those automated checks, for example, whether the code can be compiled or it conforms to the coding specification, followed by a series of automated tests (CI Automation).
- One or more reviewers will review the code (Code Review).
- Afterwards, the code is submitted to the repository and the commit history is recorded.
- After a manual or automated process, the code is packaged into a new version, an Artifact, in technical term.
- The deployment system gradually deploys the new version according to a pre-configured process. Usually it is first deployed to a test environment where integration tests are run, and possibly manual tests by the QA team. After that, it will be deployed to the pre-release/staging environment. If the verifications pass, it will eventually be deployed to the production environment. Of course, in the production environment, the new version will be gradually rolled out, which is also known as the grayscale/canary release.
The code CI/CD process, as we know, is not complicated, but it took more than 20 years for the industry to figure out and agree upon, which solves a series of problems such as collaboration, visibility, reliability, and efficiency in code changes and releases.
As for database changes, because it involves data change, that is, the state. Although the process can be borrowed from the idea of code change, it is still more complicated and requires tooling support.
Separate code changes from database changes
An application has two major components: code and data, the former is stateless and the latter is statefull. Stateless changes are relatively easy to solve, because if there is a problem with the change, you can simply roll back and be done with it. But stateful changes are much more complicated: you have to consider whether it will lock the database and lead to unavailability of the whole service, plus rollback is much harder because of dirty data.
There are two approaches to deploy the database schema change:
- Coupled: Deploy the schema change at the same time when deploying the application.
- Decoupled: Separate the schema change from the application deployment.
Coupled Database Schema Change with Application Deployment
Almost every application begins with the coupled approach. And many application frameworks such as Ruby on Rails, Django offer built-in migration facilities to do schema change, so are various ORMs. The basic idea is you write a set of SQL statements to migrate the schema forward, and supply another set of SQL statements to rollback the schema in case bad things happen. Those SQL statements are bundled with the application release, and are executed right before the new code binary starts the next time.
When small teams first start out, they usually put database and code changes together, but as the Reddit author encounters, when they scaled up, they faced problems:
- Very little control when schema change goes wrong. Application would not start and it requires manual intervention.
- Some schema changes may take a long time to finish, which means downtime when deploying the new version releases.
- Not suitable for applications where there are multiple server instances accessing the same database. Since any of the server instance may perform the schema change, and it requires extra locking mechanism to coordinate the change.
- Not suitable for team collaboration where there are dedicated DBAs or Platform Engineers to manage the databases. As for the coupled approach, the centralized DBAs or Platform Engieers don't know when the schema change happens. Instead, they will only be paged by the monitoring system that one of the instances is malfunctioning, and then spend a lot of effort to trace down it's caused by a reckless schema change made by an application team.
Sourcegaph RFC lists the typical issues with the coupled approach. And their solution is to decouple the schema change from code deployments.
Decoupled Database Schema Change from Application Deployment
The core idea of decoupled solution is to move schema change into a separate process. The typical workflow is first performing the schema change needed for the new release. If schema change goes wrong, the change will be rolled back immediately. After the schema change completes, then the team will find a time later to deploy the new code release.
The main benefit is the team now has much better control over when and how to perform the schema change. It separates the risky schema change from the code deployment during the new release cycle. We all know change contributes to most outages, and it's a good practice to separate different changes to limit the change scope and risk. You don't want to wait until the new application deployment to learn that the new schema is problematic.
On the other hand, decoupled approach does come with more overhead:
- The application code needs to be compatible with the current schema as well as the future schema. This is not a requirement for the coupled approach where the new release only starts if the schema change succeeds. Thus the application code can assume to always run against the latest schema.
- An extra process to perform the schema change.
For 1, though it requires more work, it's always a good practice to write code in a backward compatible way with the database schema.
For 2, database schema change is a risky operation, so it does demand a formal change review process.
Coupled vs. Decoupled
Coupled schema change is simple, it's suitable for self-contained application where database, backend server and frontend are bundled and deployed together. Desktop and self-contained mobile apps fall into this category. These apps are usaully small and don't perform heavy database operations. On the other hand, many web apps are separated into different components, managed by cross-functional teams and require careful database change coordination. In such case, decoupled schema change is the only viable option.
Summary
In this post, we have reviewed the challenges, mistakes for making database schema changes. We also present the best practices for teams to tackle this problem.
Developing best practices alone is not sufficient to solve database schema change problems, in the next post Top Database Schema Change Tools in 2023, we will cover various tools developed over the years and the state-of-the-art to tame the beast.




