
Let’s chat about the cumbersome database change process
Database change has long been the most critical step in a release. If you do it well, you are one step closer to improving CI/CD efficiency. As business complexity and database instances increase, it gets harder and harder to manage database change. Let's see if any of the following scenarios sound familiar:
- SQL scripts are scattered in various computers, and any modification needs repeated manual confirmation.
- Change requests need to be submitted in multiple systems, which can easily be missed.
- DBA only intervenes to review the SQL right before execution: blocking the problematic SQL will delay the release while passing it will create long-term hidden problems.
- Change requests are complex: imagine n slightly different SQL scripts for multiple application versions or different tenants. If SQL scripts are stored in standard document folders, that’s just a recipe for disaster.
- There is no way to archive and audit the change scripts afterward.
They may not sound so bad if you only need to manage one or two databases, but when you face as few as a dozen to 1,000+ instances, this will be torture. We have a platform to manage code, a variety of issue trackers, and multiple SQL review tools, but why is this process still such a pain in the ass?
All inefficient collaboration can be backtracked to fragmented processes and unshared information, if we can develop a complete Database CI/CD workflow, and break the wall between developers and DBAs, will it improve efficiency?
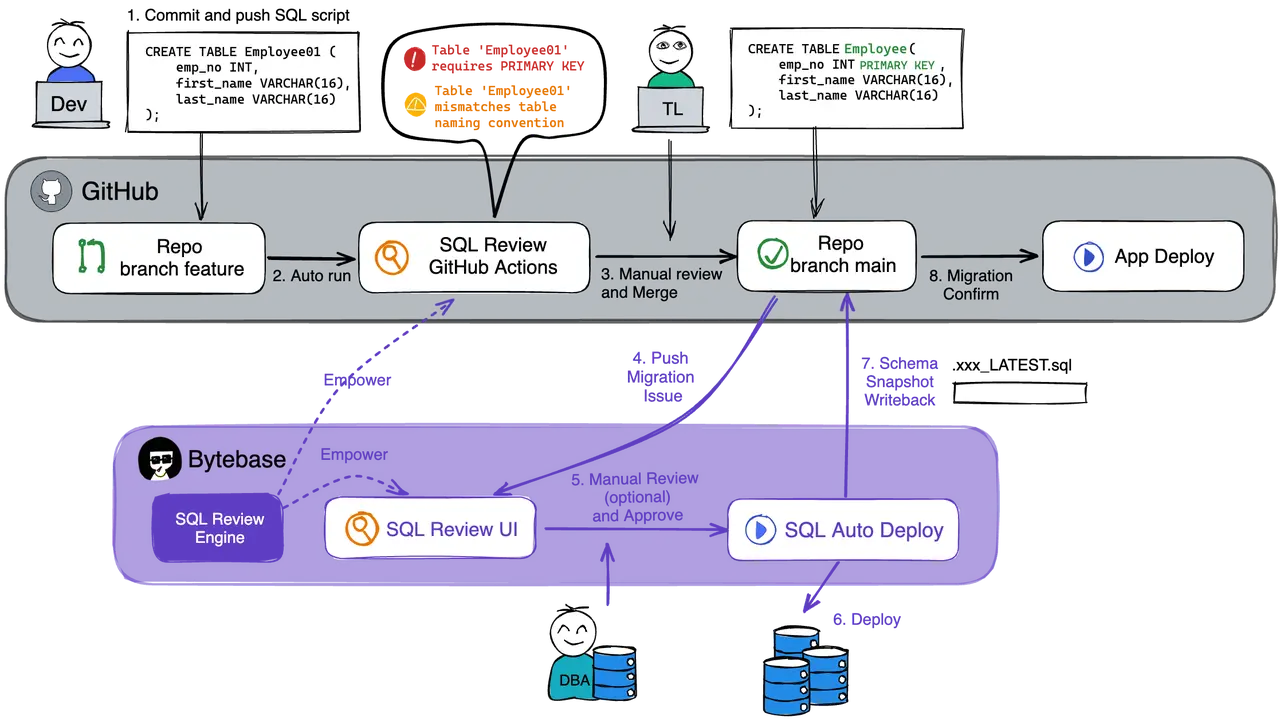
In this article, we will cut through the lens of developer workflow and explore how to design a pragmatic VCS integration solution.
Define your organization's iteration process
Organizations are influenced by department divisions and tech stack. These eventually form their release process, which is difficult to change. There are many ways to categorize the release process. Since our goal is to optimize change management, let’s divide it into two by application iteration.
Centralized iteration: couple multiple applications together, release one version at a time, and manage them by batch. This works for functions that are tightly coupled together, so changes need to be planned holistically for up and downstream businesses. This development process is commonly found in traditional industries with high business complexity, such as finance.
Decentralized iteration: to improve business iteration efficiency, organizations try to decouple applications as much as possible, with each team independently responsible for the development and release of its application or module. Some emerging IT and SaaS companies are adopting this model, of which microservices are a typical practice.
However, most companies (huge ones, at least) will not fully adopt only one form: they usually adopt different iteration models in different departments, between core and sideline business, critical and supporting functions. We must combine different models and design the most suitable Database CI/CD solution for different models.
Define database management boundary
With a defined iteration process, it is natural to derive different ways of database management. It is essential to clearly define the management boundaries of the database across different teams, as the different management styles determine how the process should be optimized. Since the DBA is the database admin, so our management boundary analysis should revolve around this role. While some organizations have mature DBA teams, others may not have a DBA at all, but in any case, database change is inevitable, and the difference is simply who is responsible for it. There are three mainstream practices for managing databases:
- The DBA is fully responsible for all the database work, the boundary is drawn between the DBA and the devs. The devs are only responsible for submitting change requests and are far from database management.
- The development teams are fully autonomous. This is usually because there is no DBA (or platform engineering) in the organization. The management boundary is drawn between different development teams, and each project team is only responsible for its own database.
- The DBA is in charge of database-related work, but the devs are more deeply involved. Some critical work still belongs to the DBA, while some work is assigned to the development teams, and also divided by project.
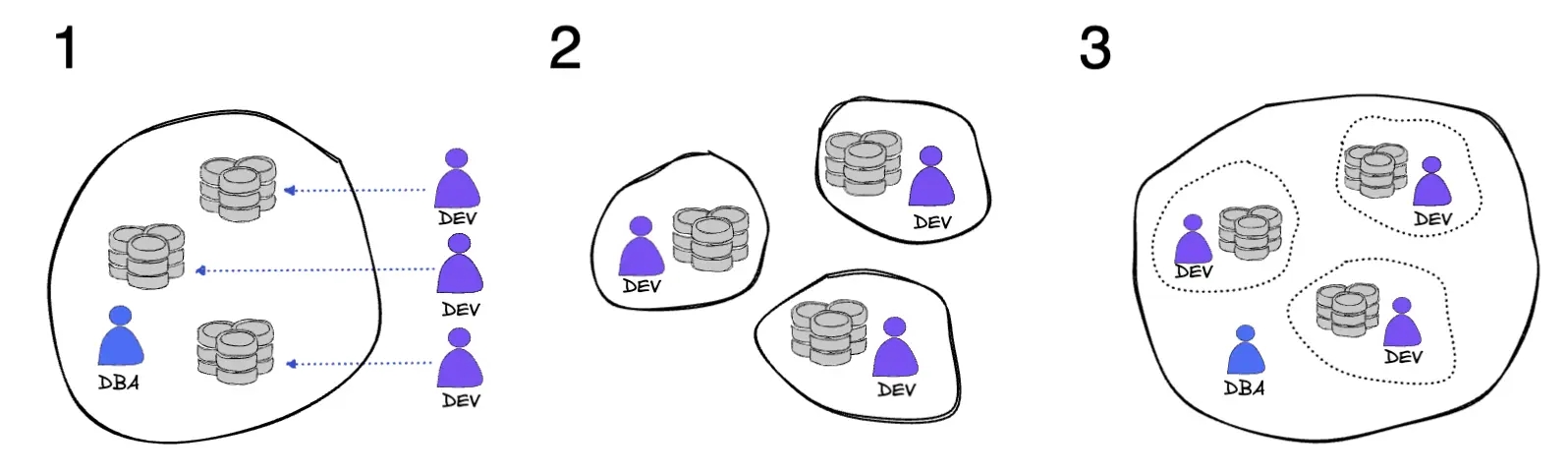
In an organization aiming at Database DevOps, the development team should be encouraged to participate more in the database change work, while the DBA should work with infra and SRE teams to develop a database management framework. This includes tools selection, review policy development, and automated CI/CD process implementation to improve overall efficiency by empowering the devs instead of dealing with mundane work alone. After all, for most organizations, a single DBA often faces hundreds of devs. With this goal in mind, we recommend the third model in which the DBA (or underlying platform engineering team) works with the development team to build the database management framework and allows the development team to have controlled access to the database.
Of course, different organizations should be more specific in deciding which tasks to give autonomy to the development team, considering their own R&D and business processes.
- Organizations using centralized iteration usually have a more complex business as well. The DBAs need to have more profound control over each specific change. However, this does not prevent collaboration with the devs in the early stages such as testing and pre-integration, which will significantly improve the efficiency for the official release.
- In organizations using decentralized iteration, the development teams are in charge of most of the work, including reviewing changes to the production environment, while a small number of DBAs (or none at all) are involved in only some of the most critical aspects or solving more complex problems.
Implementing GitLab/GitHub integrated Database CI/CD
Once you’ve defined your organization’s R&D processes, it’s time to get down to business.
Introducing VCS for Change Script Management #GitOps
The first thing is to get your SQL scripts in order - SQL is code, too. And it makes sense to use a version control system (VCS) such as GitLab or GitHub to manage SQL. To ensure manageability, we need to structure the SQL scripts in the VCS in a way that makes sense.
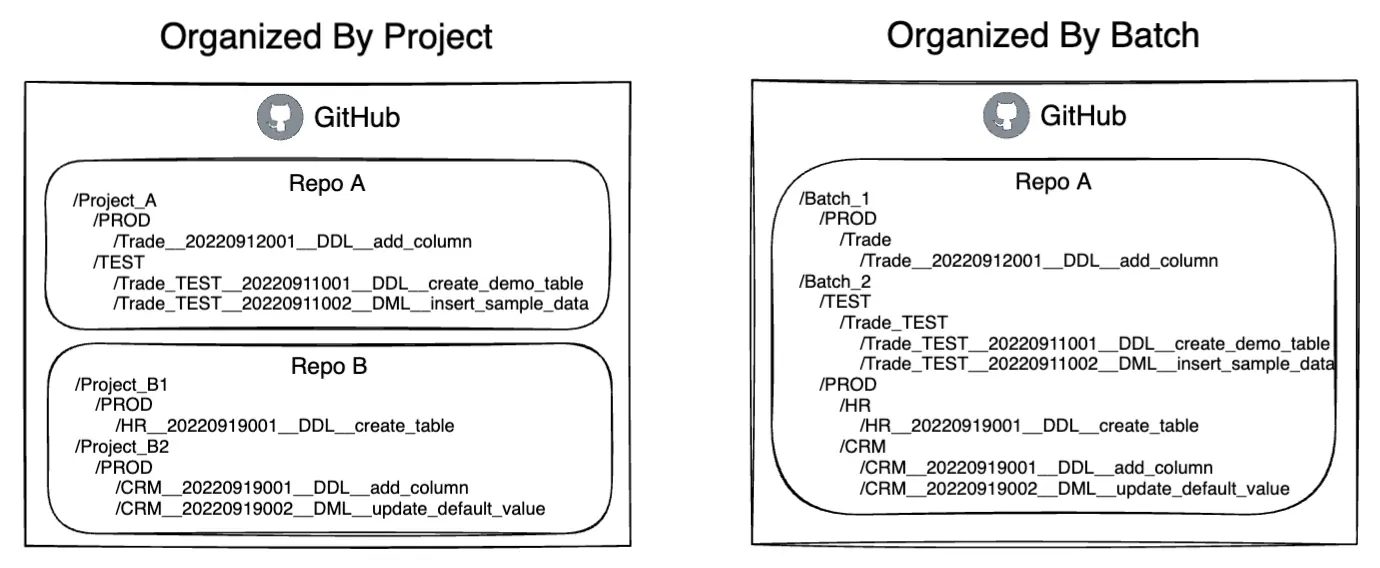
By project
For organizations using decentralized iteration, most of the time, each database belongs to a specific application, which can be seen as the management boundary. Bytebase uses this model, i.e. managing the database by application project, which is in line with the habits of most organizations. A good practice to group change scripts is by application project name, as the root directory. These scripts can be stored in their respective application code repositories or in a single code repository, depending on the organization’s management habits.
By change batch
For organizations with centralized iterations, since each batch of changes may involve multiple applications and these scripts are interrelated and affect each other, it’s better to store change scripts grouped by batch in VCS rather than by application, which means that each batch directory contains change scripts for multiple databases. For easy management, it is recommended to group scripts by environment or database name. In Bytebase, it is recommended to group the scripts by application to manage database review access.
Have the devs perform SQL review: the shift-left approach
This shift-left approach makes it possible for the SQL scripts to be reviewed as they are submitted to VCS,
To avoid complex SQL blocking your release, the shift-left approach should be introduced: SQL review is integrated into the existing developer workflow, making it possible for the SQL scripts to be reviewed as they are submitted to VCS. Common checks include:
- Syntax: standard SQL syntax checking.
- Executability: does the object associated with the statement exist?
- Naming: table, index, field names, etc. should be meaningful and easy to manage, for example, index names should contain corresponding tables and fields, and no special characters in table names.
- Table creation: mandatory primary key, comments, etc.
- Index rules: restrict index type, restrict the number of index fields, restrict index field type, etc.
- Field rules: such as restricting the type, length, default value of fields, etc.
- Query restrictions: such as query must have filter conditions, etc.
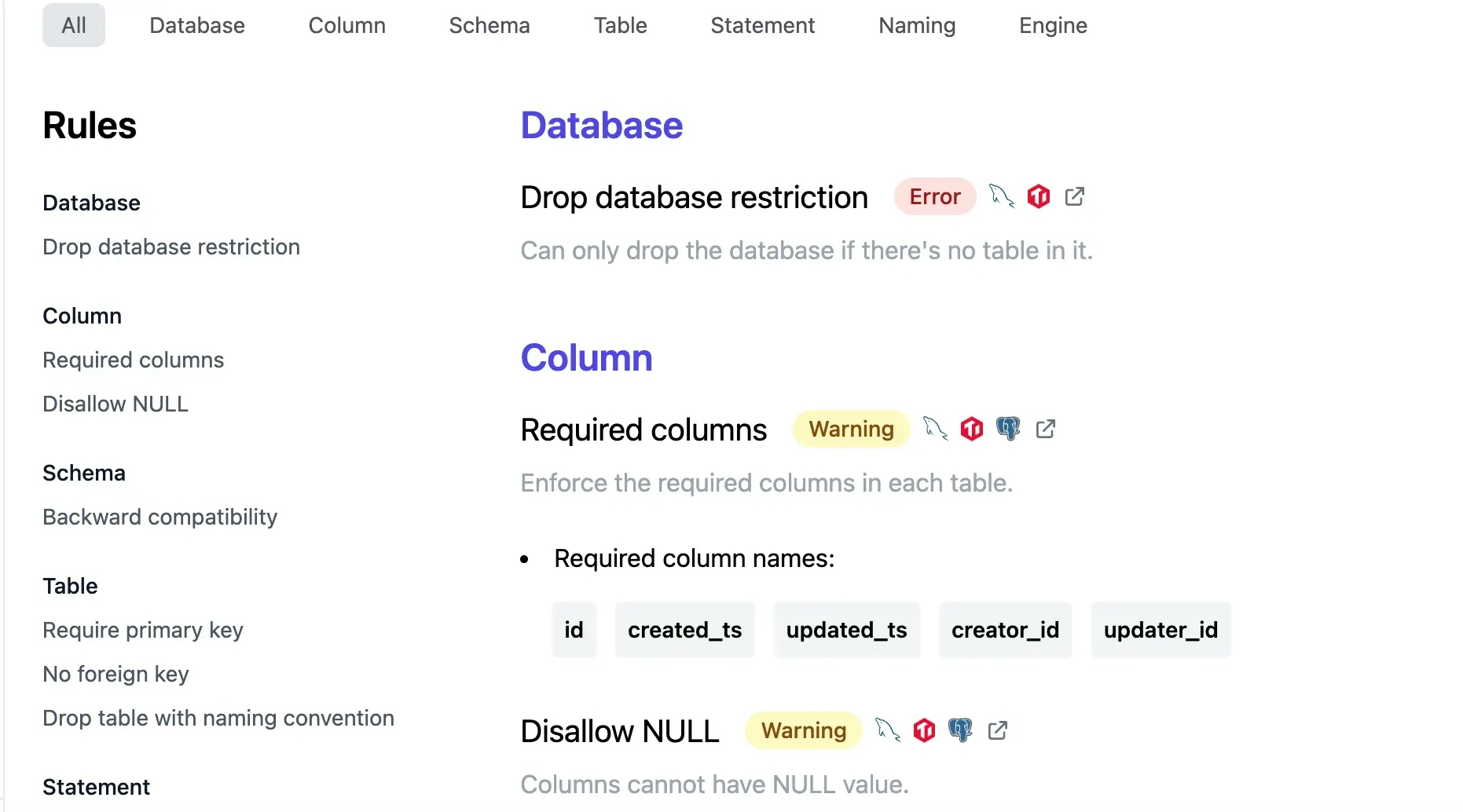
Bytebase has ~100 standard built-in SQL Lint and supports configuring review rules that incorporate your business needs. You can choose one of the following rule levels: Error, Warning or Disabled. When the rule is Disabled, it will not take effect. To better implement the rules, it is highly recommended that the DBA and the dev teams agree on the SQL review rules, and rule levels and decide which rules should be enabled at which stage. In prod, an application often includes multiple environments: from dev, testing, staging to prod. To balance efficiency and security, different review policies should be used at different stages. Still, it is recommended that SQL scripts should be included in VCS management from the testing environment. An example of a strategy:
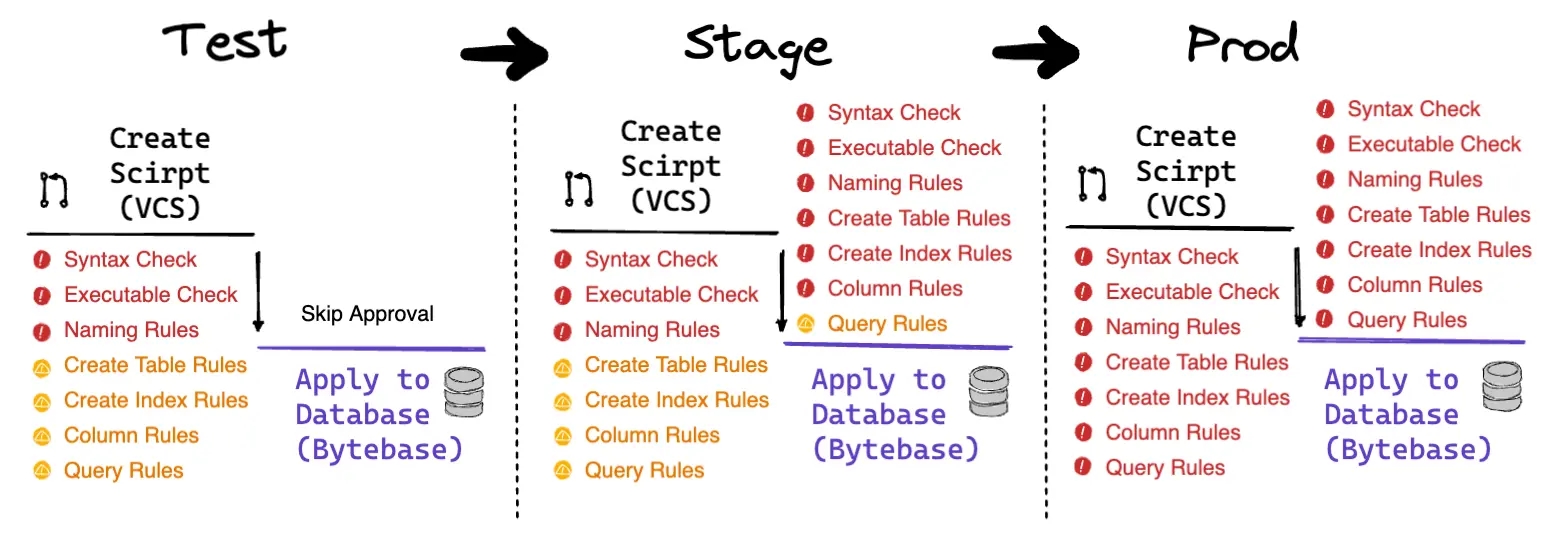
- When creating your scripts, the SQL statements are pre-checked by Bytebase's VCS-integrated review capabilities to help identify violations.
- During the execution phase, Bytebase will initiate a secondary check. The closer you get to prod, the tougher the rules.
Defining an automated deployment workflow
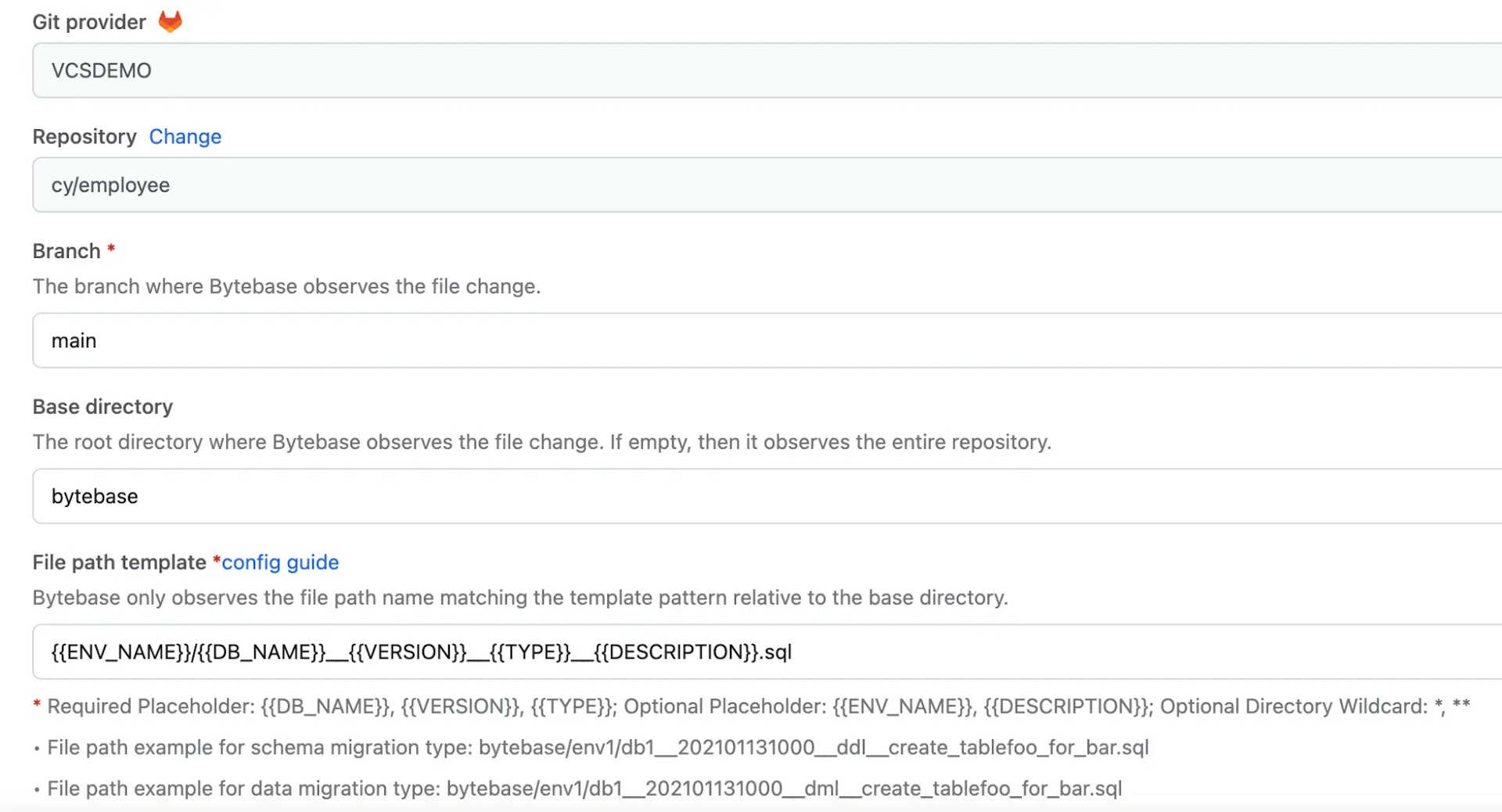
Bytebase aims to fully automate the change release process. This is achieved by identifying script paths under a given code repository, so that each script can be associated with a given database. Let's look at an example of Bytebase's path matching template: Base_DIR/{{{ENV_ID}}/**/{{DB_NAME}}__{{VERSION}}__{{TYPE}}__{{DESCRIPTION}}.sql
In this directory structure,
- Base_DIR is the specified root directory (can be multi-level).
{{ENV_ID}}should match the destined environment identifier of the database.- ** is a wildcard to match one or more directories.
{{DB_NAME}}is the database name to be changed.{{VERSION}}is the version number of this change.{{TYPE}}is the change type (DDL or DML).{{DESCRIPTION}}is an optional description string.
By combining placeholders with wildcards, you can precisely match the target database managed by Bytebase in any directory structure.
If you manage scripts by application project, the script categorization structure in VCS corresponds to the database categorization structure in Bytebase, and each Project in Bytebase monitors only the script changes in the directory corresponding to its own.
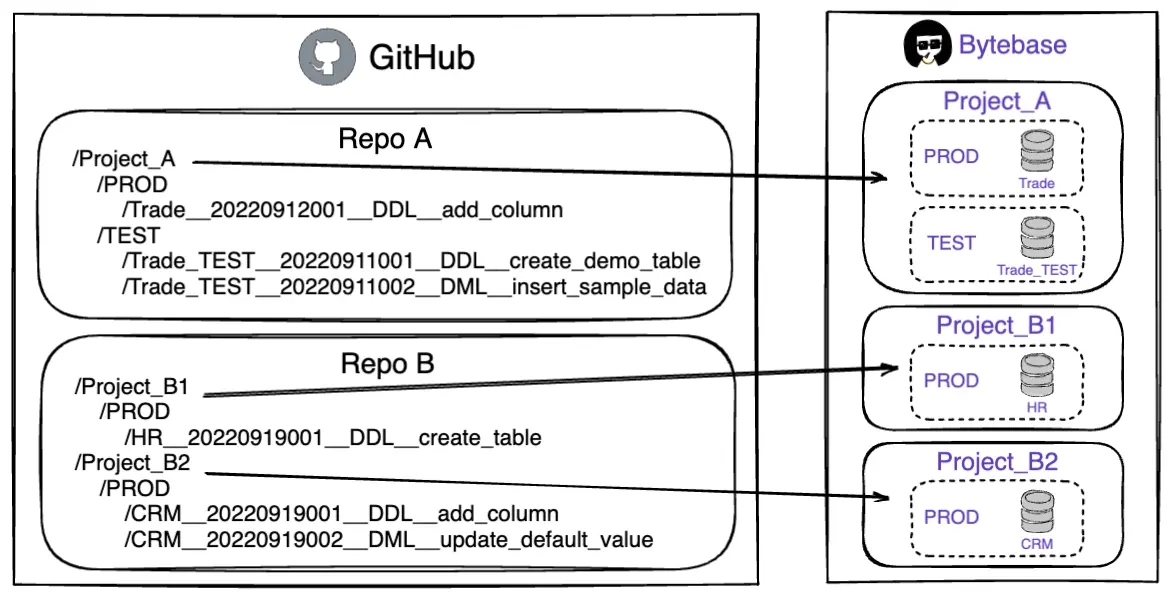
If you manage scripts by change batch, the change scripts in each change in VCS have a one-to-many relationship with the database sorting structure in Bytebase, but each change script can still be precisely matched to the specified database by setting the placeholders appropriately.

Finalize configuration in the Bytebase Console
The last thing we need to do is to implement the above in Bytebase.
This process can be divided into three main tasks:
-
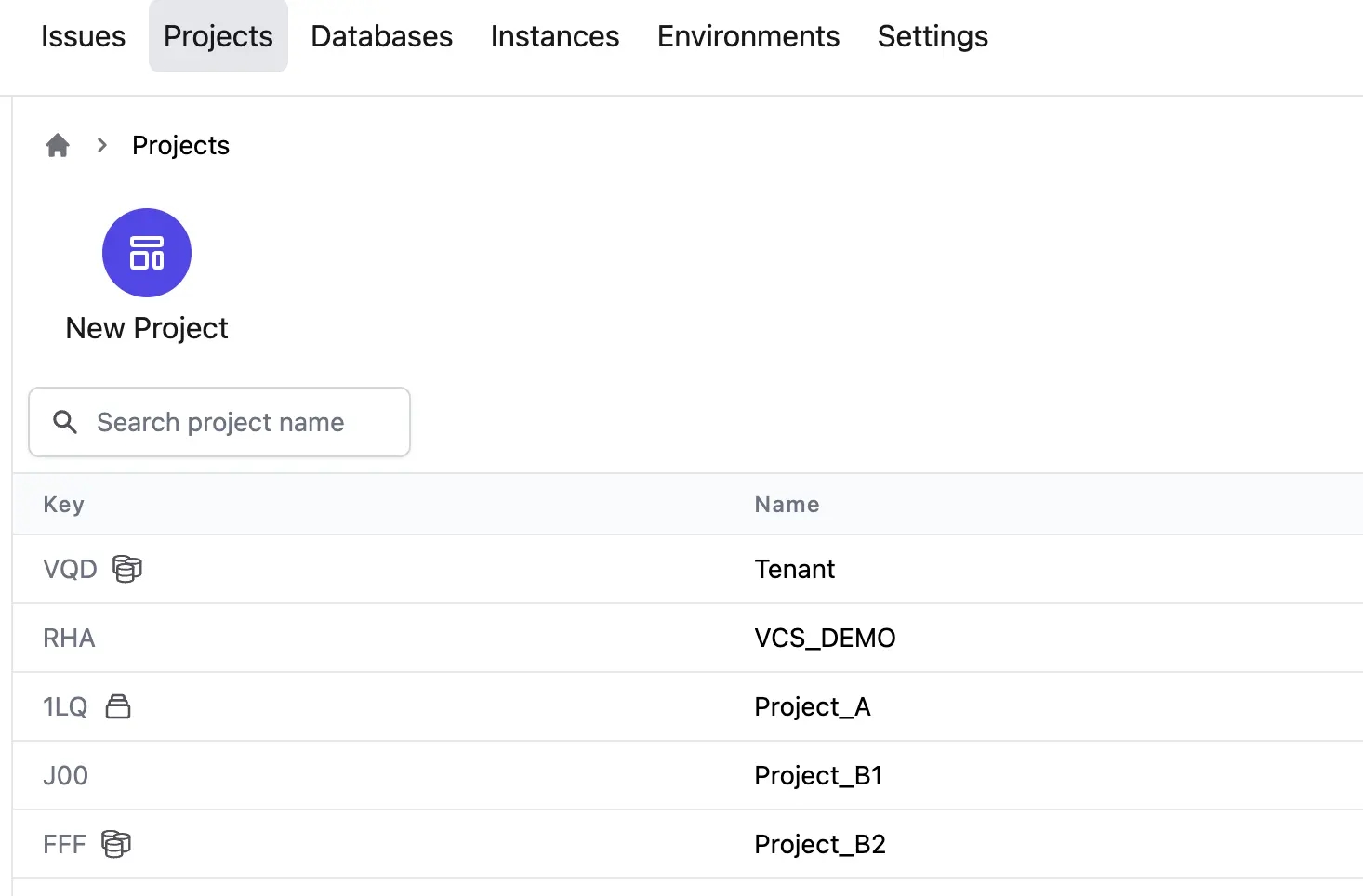
Create a Project. Divide the databases into groups according to defined database management boundaries, and assigning them to different projects, with the development team's management boundaries defined by the project and the DBA/Ops/Platform teams having global access.
-
Create Schema review policy. Set up review policy for each environment, taking into account the specific policy and rule levels agreed upon with the development teams.
-
Set up GitOps. Configure the GitOps workflow in a given project to monitor changes in the VCS and automatically kick start the review process.
For a more detailed implementation, please refer to How to Setup Database CI/CD with GitHub.




