Database CI/CD and Schema Migration with Spanner

A series of articles about Database Change Management with Spanner.
- Database Change Management with Spanner (this one)
- Database Change Management with Spanner and GitHub
Spanner is a distributed SQL database management and storage service developed by Google. It provides features such as global transactions, strongly consistent reads, and automatic multi-site replication and failover.
This tutorial is a step-by-step guide to set up Database Change Management for Spanner in Bytebase. With Bytebase, a team can have a formalized review and rollout process to make Spanner database schema change and data change.
Bytebase provides a GUI for teams to perform database changes and retain full change history. You can use Bytebase free version to finish the tutorial.
At the end, there is a bonus section about Schema Drift Detection for those advanced users.
Features included
- Change Workflow
- SQL Editor
- Change History
- Drift Detection
Prerequisites
Before you start, make sure you have:
- An Spanner instance.
- Docker installed.
Step 1 - Deploy Bytebase via Docker
-
Make sure your Docker is running, and start the Bytebase Docker container with following command:
docker run --rm --init \ --name bytebase \ --publish 8080:8080 --pull always \ --volume ~/.bytebase/data:/var/opt/bytebase \ bytebase/bytebase:2.15.0 -
Bytebase is now running via Docker, and you can access it via
localhost:8080.
-
Visit
localhost:8080in your browser. Register the first admin account which will be grantedWorkspace Admin.
Step 2 - Add an Spanner Instance to Bytebase
In Bytebase, an Instance could be your on-premises MySQL instance, an AWS RDS instance etc, in this tutorial, an Instance is your Spanner instance.
-
Visit
localhost:8080and log in asWorkspace Admin.
-
On the home page, click Add Instance.
-
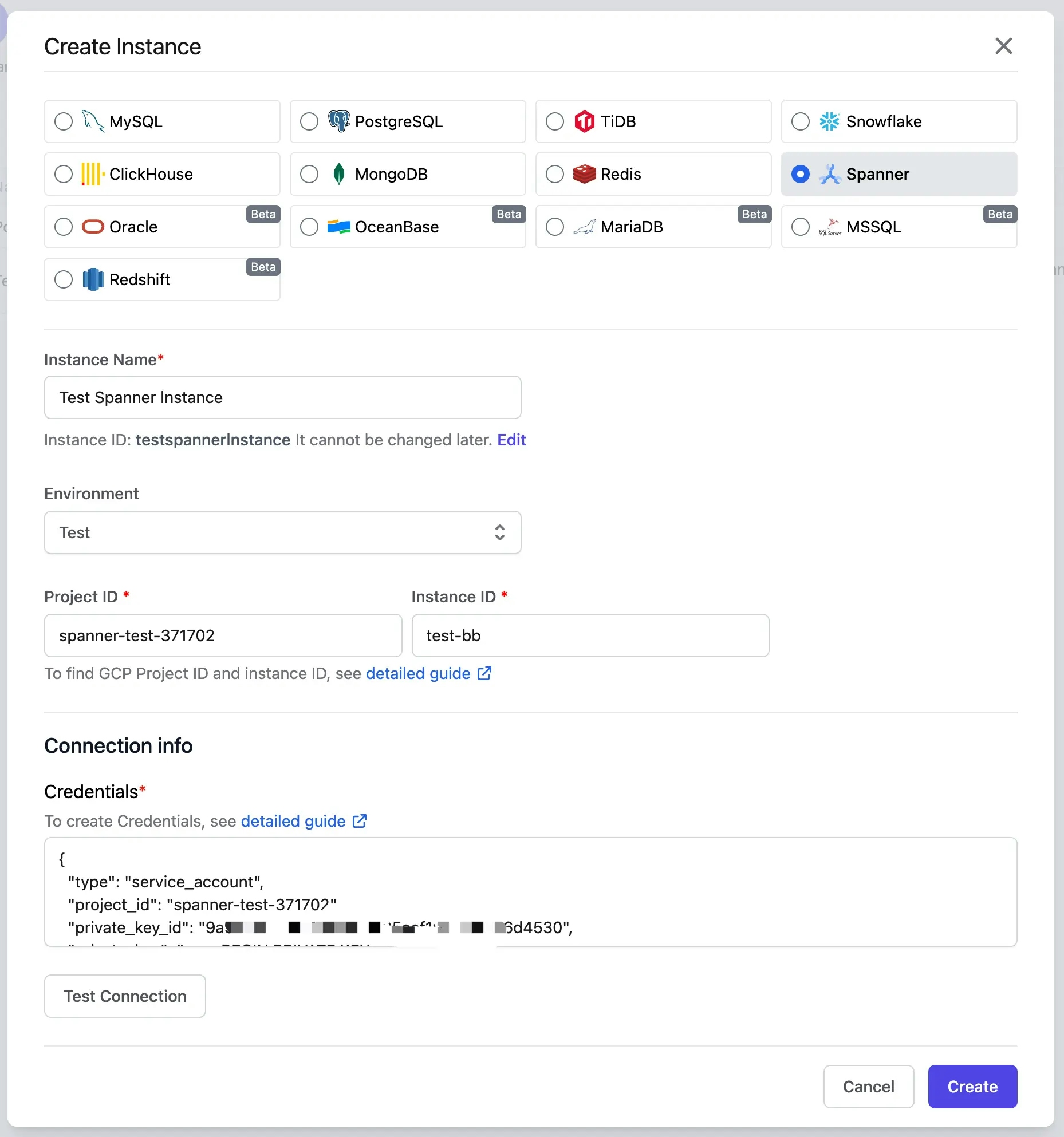
Choose
Spanner, fill in the fields and click Create. Pay attention to these fields:
- Instance Name:
Test Spanner Instance. - Environment: choose
Test, if you chooseProd, you'll need manual approval for all future change requests by default, let's keep it simple for this tutorial. - Project ID and Instance ID: How to Find Project ID and Instance ID
- Credentials: How to Create a Service Account for Bytebase
Step 3 - Create a Project
In Bytebase, Project groups logically-related Databases, Issues and Users together, which is similar to the project concept in other DevTools such as Jira and GitLab. So before you deal with the database, a Project must be created.
-
Click Projects on the top navigation bar.
-
Click New Project to create a new project
Demo UI, key isdemoui, mode isstandard. Click Create.
Step 4 - Create an Spanner Database via Bytebase
In Bytebase, a Database is created by CREATE DATABASE xxx. A database always belongs to a single Project. An Issue represents a specific collaboration activity between Developer and DBA for when creating a database, altering a schema. It's similar to the issue concept in other issue management tools.
- Click Projects >
Demo UIon the left sidebar. Click New DB to create a new database. You can click Transfer in DB to transfer in your existing databases. - Fill the form with Name -
test_db, Environment -Test, and Instance -Test Spanner Instance. Click Create. - Bytebase will create an issue to create the database automatically. As it's the
Testenvironment, the issue will run without waiting for your approval by default and then becomeDone.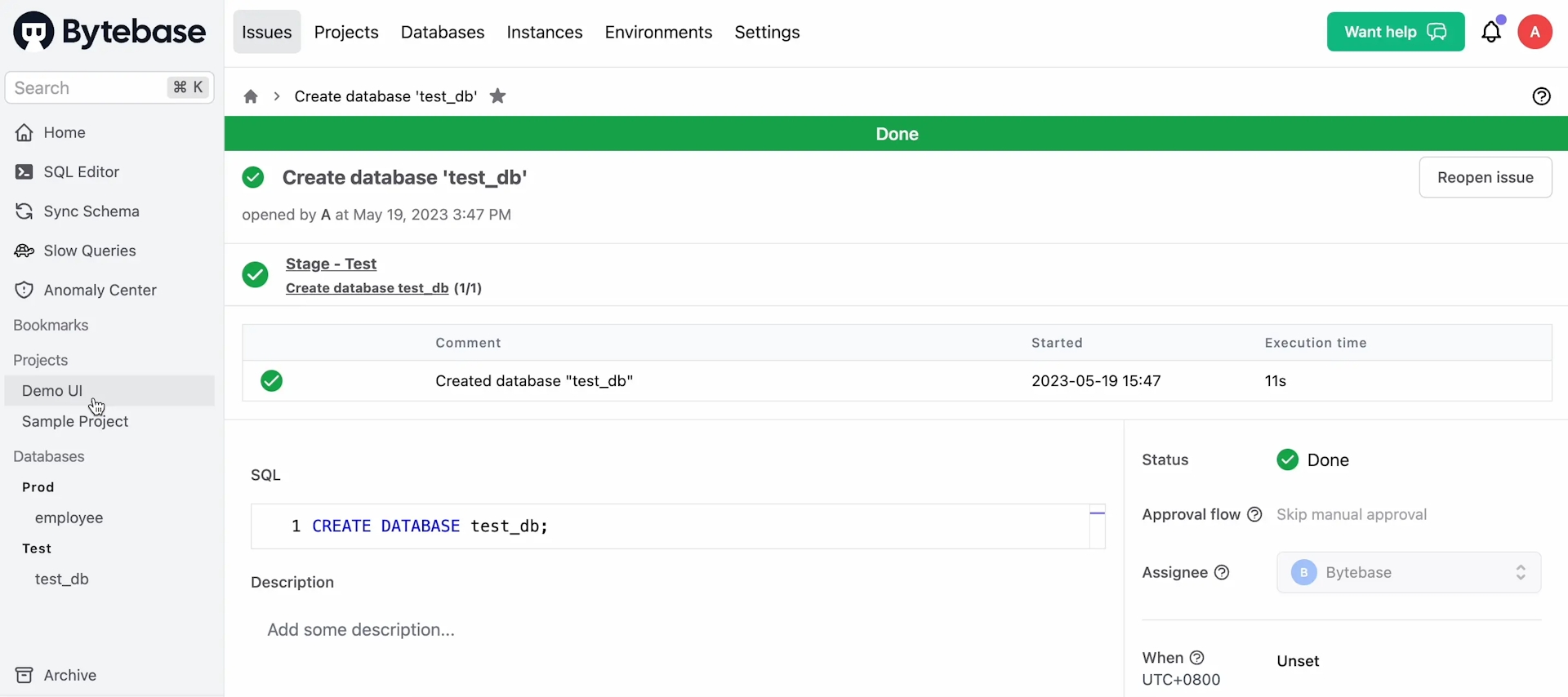
Step 5 - Create a Table in Spanner via Bytebase
In Step 4, you created an issue to create a database using UI workflow and then executed it. Let’s continue to create a table.
-
Go to the project, and click on Alter Schema.
-
Choose
test_dband click Next. -
Input the SQL as following and click Create.
CREATE TABLE t1( Id INT64 NOT NULL ) PRIMARY KEY(Id); -
The issue is automatically approved by default since it’s for the
Testenvironment. The issue will becomeDoneafter execution.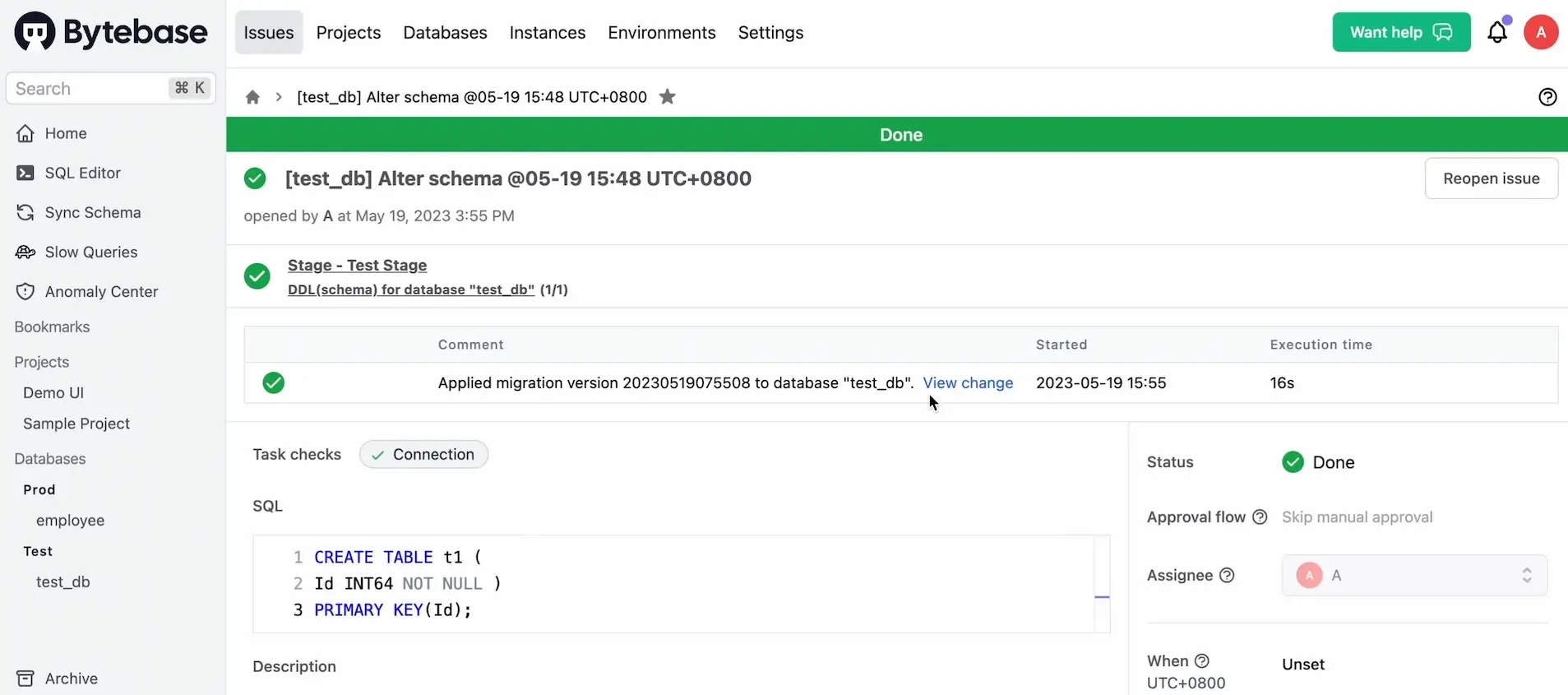
-
From the issue page, click View change, and you can see schema diff.
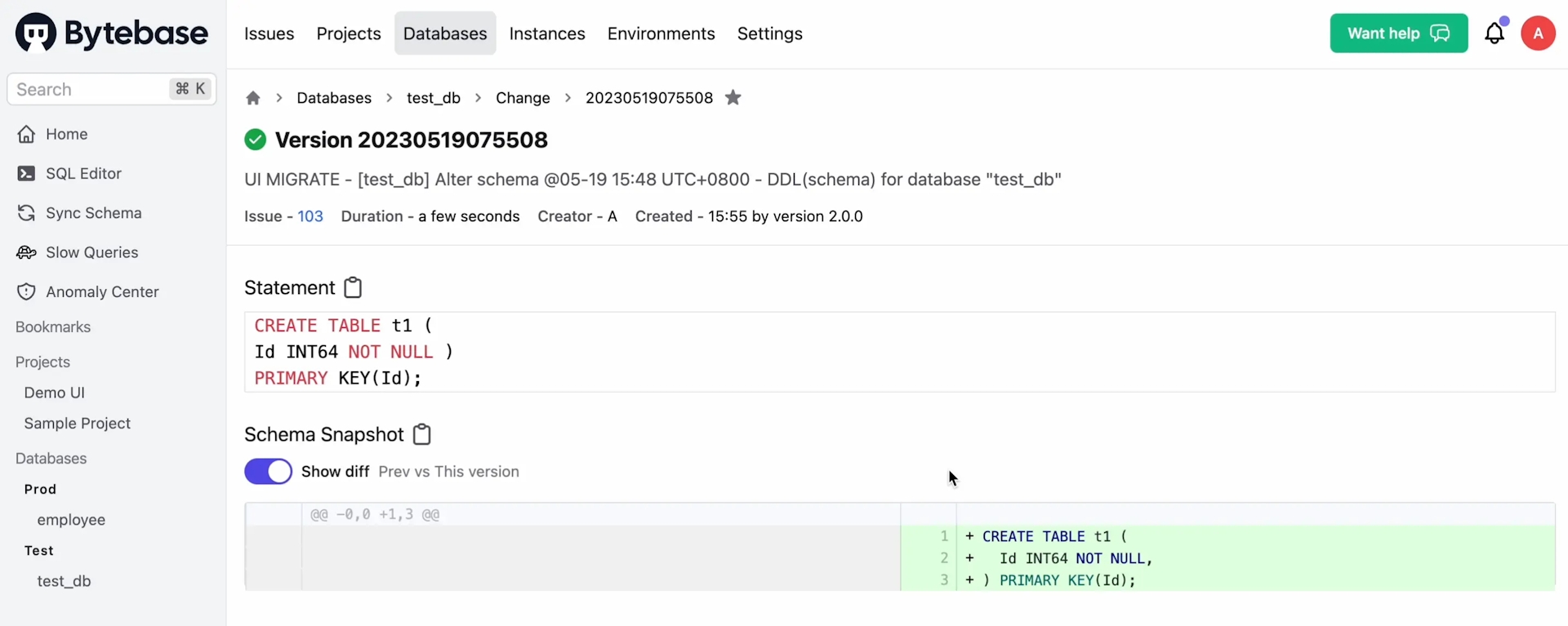
Step 6 - Add Some Data and Query via SQL Editor
-
Repeat Step 5 to alter schema again, but this time input this SQL:
ALTER TABLE t1 ADD COLUMN Name STRING(255); -
Go to the project, and click Change Data.
-
Choose
test_dband click Next. -
Fill in the SQL as follows and then click Create.
INSERT INTO t1 VALUES (1, 'Adela'); -
Wait for its execution and then the issue will become
Done. -
Click SQL Editor on the left side bar. Input the query and click Run. You can see the new row is there.
SELECT * FROM t1;
Bonus Section - Schema Drift Detection
To follow this section, you need to activate the Enterprise Plan (you can start a 14-day trial directly, no credit card required).
Now you can see the full change history of database test_db. However, what is Establish new baseline? When to use it?
By adopting Bytebase, we expect teams to use Bytebase exclusively for all schema changes. Meanwhile, if someone has made Spanner schema change out side of Bytebase, obviously Bytebase won’t know it. And because Bytebase has recorded its own copy of schema, when Bytebase compares that with the live schema having that out-of-band schema change, it will notice a discrepancy and surface a schema drift anomaly. If that change is intended, then you should establish new baseline to reconcile the schema state again.
In this section, you’ll be guided through this process.
-
You can use an external GUI or terminal to make a change to
test_db. In this tutorial, we use Bytebase SQL Editor’s Admin mode which also counts when we say change outside of Bytebase. Go to SQL Editor, and switch to Admin mode.When you make a change in Admin Mode, it will not record any history as in a normal process www.bytebase.com/docs/sql-editor/admin-mode
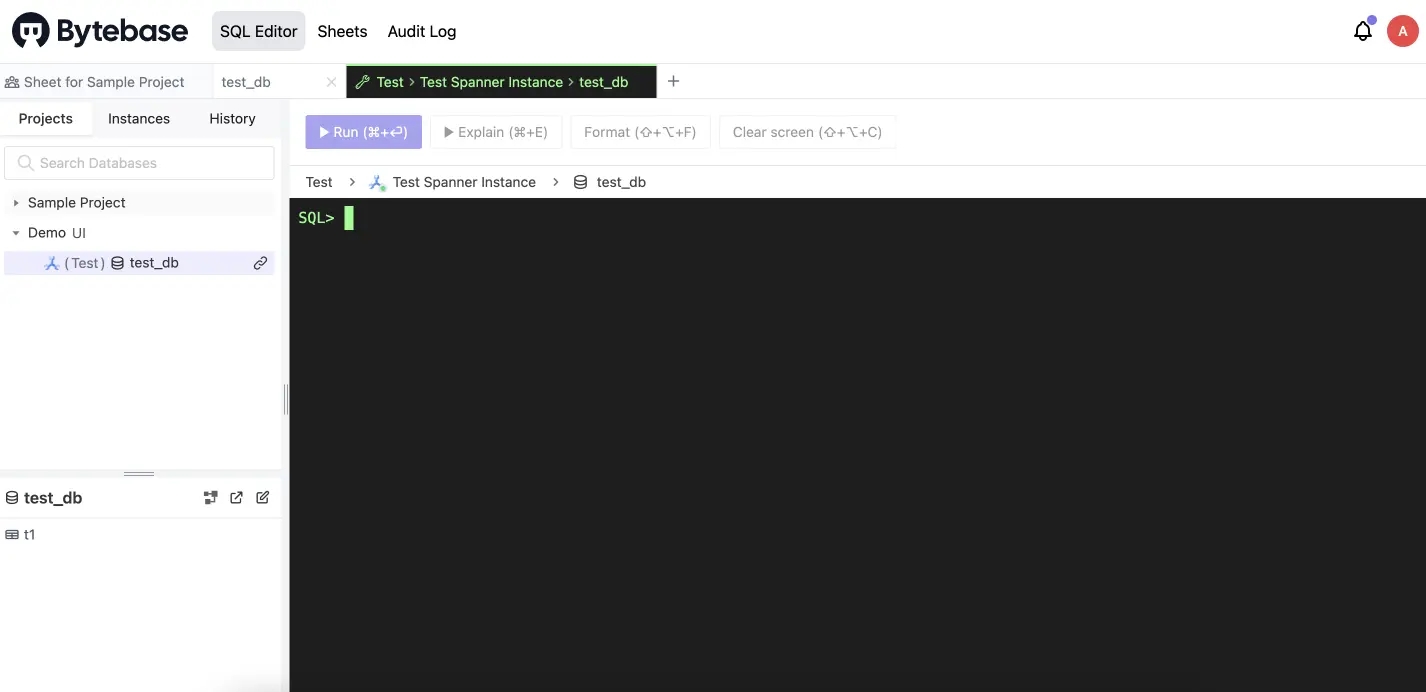
-
Paste the following and then press Enter:
ALTER TABLE t1 ADD COLUMN Gender STRING(255); -
Paste the following and then press Enter to verify it’s there:
SELECT table_name, column_name, data_type FROM information_schema.columns WHERE table_name = 't1'; -
Wait for 10 mins (as Bytebase does the check roughly every 10 mins). Go to Anomaly Center, and you can find the Schema Drift.
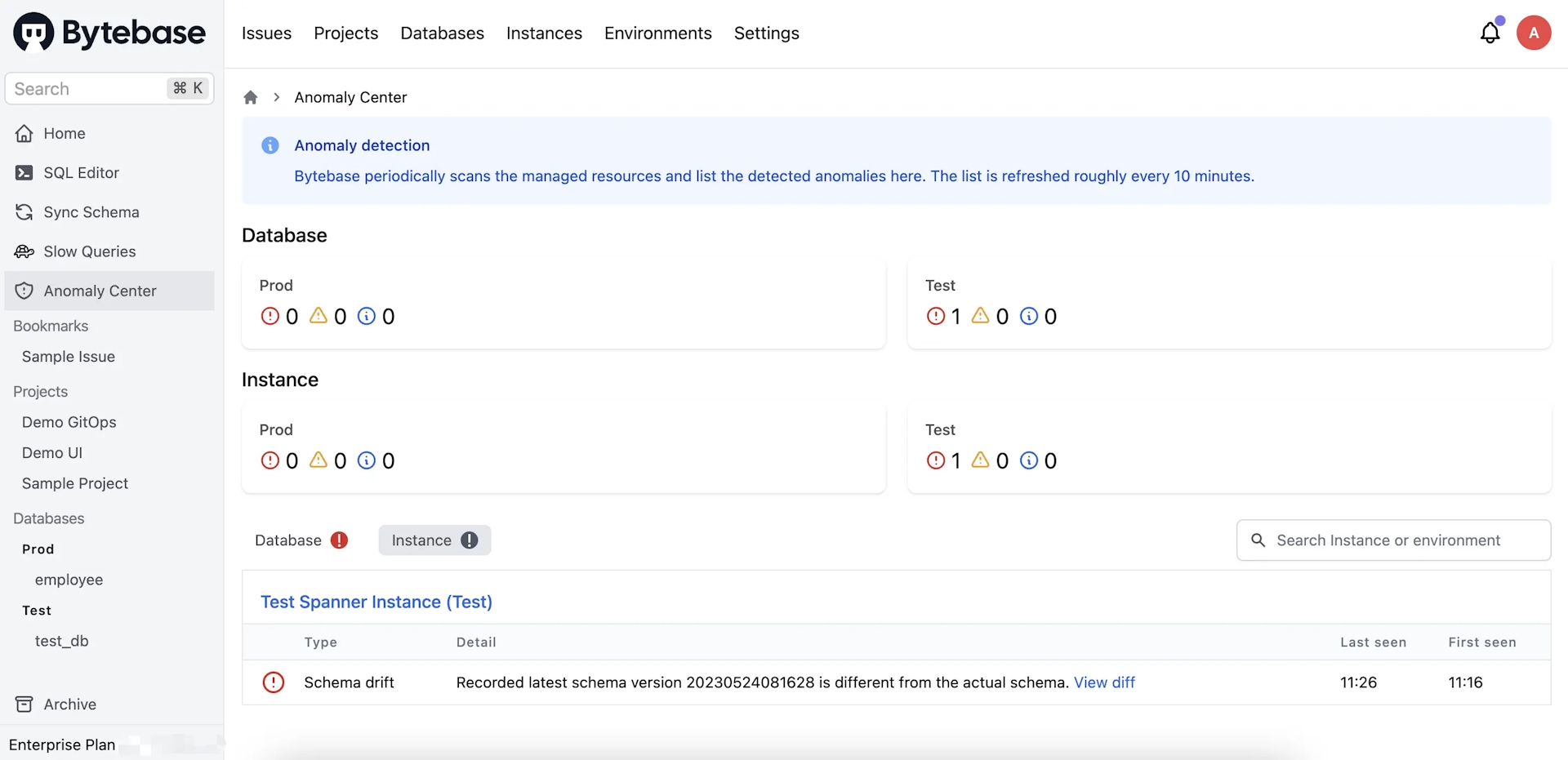
-
Click on View diff, you will see the exact drift.
-
You may also find the drift by clicking Databases >
test_db.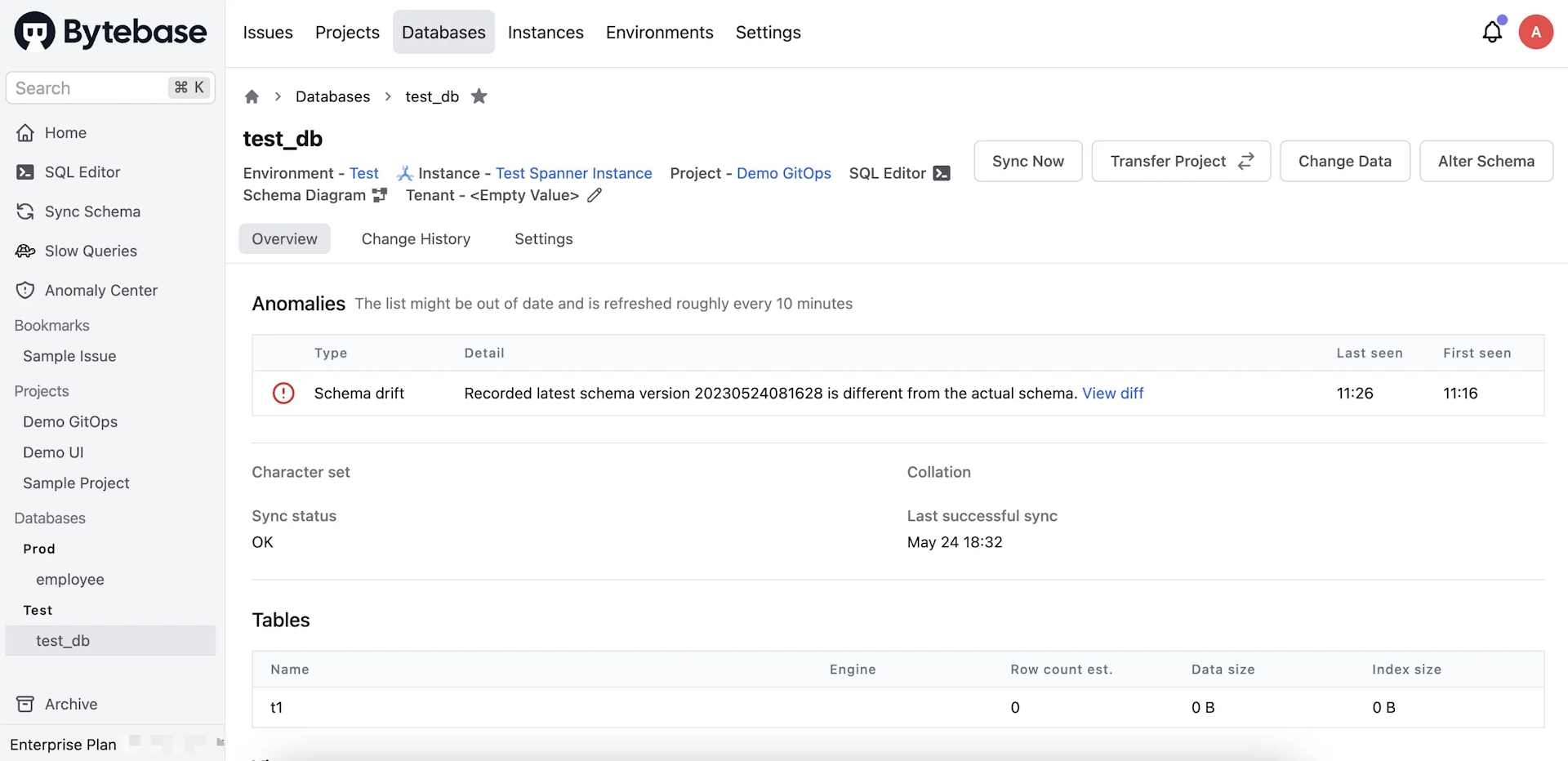
-
Go to Databases >
test_db> Change History and click Establish new baseline, this step establishes a new baseline to reconcile the schema state from the live database schema. -
Bytebase will create an issue to establish the new baseline, click Create, and then Resolve to mark it done.
-
Go back to Databases >
test_dbor Anomaly Center, and you will find the drift is gone.
Summary and What's Next
Now you have connected Spanner with Bytebase, and used the UI workflow to accomplish schema change and data change. Bytebase will record the full change history for you. Furthermore, the Enterprise Plan is equipped with Schema Drift Detection to detect out-of-band schema changes performed outside of Bytebase.
In the next post, you’ll try out GitOps workflow: store your Spanner schema in GitHub and Bytebase will pick up the changes to the repo, bringing your Spanner change workflow to the next level, aka Database DevOps - Database as Code.
